为什么要进行性能优化
对于一个应用APP来说,不仅要有优秀的界面设计和功能交互,更重要的是能否有很好的性能了,能否给用户带来很好的用户体验。
众所周知,Android系统作为以移动设备为主的一款操作系统,硬件配置有一定的限制,虽然配置现在越来越高级,但仍然无法和PC相比,在CPU和内存上的使用不合理或者耗费资源多时,就会碰到内存不足导致的稳定性问题、CPU消耗太多导致的卡顿问题等。
所以这时进行性能优化就显得很重要了。性能问题主要可以分为下面四个类别:
- 流畅
- 稳定
- 省电
- 省流量
绘制优化
绘制原理
在学习自定义View时我们知道,整体结构是一个树的结构,在View绘制时有三个过程:Measure,Layout,Draw。在Measure和Layout中获取View的位置和大小时,都是通过从根节点出发,一层一层往下遍历的,所以层级越深,元素越多,他的耗时就越长。
在Draw绘制时,分为软件绘制(CPU)和硬件加速(GPU),开启硬件加速后,CPU只负责测量,布局这些数据的记录,然后GPU会对数据进行栅格化,最后渲染好后会放到buffer缓冲区里面存起来,供display(显示控制器)传递给屏幕。显然,启用了硬件加速后,在UI的显示和绘制效率远远高于CPU绘制,但是硬件加速也有些缺点,比如GPU的功耗比CPU高,自定义View中的一些接口和函数不支持硬件加速以及所需内存大。
栅格化,就是将矢量图形(如三角形,直线等等)转化为像素数据的这一个过程,这些像素数据就是最终渲染到屏幕上的图像。
刷新机制
FPS:即帧率,指的是屏幕每一秒传递的帧数,理想情况下,在60FPS时我们人眼就会觉得不卡,所以APP的性能目标就是如何保持60帧,即每一帧1000/60=16ms的时间来处理数据。
16ms刷新一次屏幕就代表着display从buffer中拿取数据并显示出来的固定频率,但是CPU和GPU写入数据的频率不是固定的。

- VSYNC:是Vertical Synchronization(垂直同步的缩写),可以看成一种刷新信号,当CPU接受到这个刷新信号时就会开始计算下一帧的画面的数据,而底层在接受到这个刷新信号时就会切换下一帧的画面。而当APP界面没有必要刷新时,CPU就不会计算下一帧的画面,但是底层仍会切换这一帧的画面,但我们看上去是没有变化的。
- Display:显示数据
我们在理想情况下,假设16ms为一个周期:
每当我们收到这个VSync信号中断后,CPU就会开始处理下一帧的数据,同时display会切换下一帧的画面。
普通刷新机制

这种情况下即使CPU/GPU执行完毕后仍有空余时间,此时是不会触发下一帧的计算的而是会等到这个周期结束,下一次刷新信号中断后才会继续。
双缓冲刷新机制
在上面的这个刷新流程中,我们容易发现一个问题,如果display在从缓存区中读取数据时,GPU同样也在向缓冲区中缓存数据,此时会发生屏幕一部分是一帧,另一部分则是另外一帧了,就很影响观感了,因此我们引入了双缓冲。顾名思义,此时就有两个缓冲区,其中一个成为Front Buffer,另外一个成为Back Buffer。UI总会现在Back Buffer中绘制,然后以一定的频率与Front Buffer进行交换,渲染到显示设备中。交换频率通常也为一秒六十次,此时一定是Back Buffer的数据准备好后,才会进行交换并显示到屏幕上,与屏幕刷新频率保持了同步。

如果CPU/GPU绘制的时间超过了16ms时,那么就会当VSYNC信号来临时,Back Buffer中的数据没有准备好,故只能继续显示前面一帧的画面,而当数据准备好后,下一个VSYNC信号还没有到,此时就会浪费很大一部分空白时间。这种情况就叫做==丢帧==。
在Android 4.1以后,引出了第三个缓冲区:Triple Buffer。Triple Buffer利用CPU/GPU的空闲等待时间提前准备好数据,并不一定会使用。但我们在大部分时间仍然用的是双缓冲机制。
卡顿的原因
从上面的分析中,我们可以很容易的得出卡顿的原因主要是有以下两方面:
- 绘制每一帧所消耗的时间太长
- VSYNC信号到来时还没有准备好数据导致丢帧
对于第二点,主要是因为主线程太忙导致的,所以我们应尽量让UI线程不要执行大量数据计算或者网络请求等耗时工作。第一点,我们通常需要在UI绘制和布局上进行优化。
过度绘制
过度绘制,即同一个像素点在同一帧内被绘制了多次,如果不可见的UI也在做绘制的操作,就会浪费大量的CPU和GPU资源。
可以打开开发者模式-调试GPU过度绘制,来查看过度绘制情况。

蓝色、淡绿、淡红、深红代表了4种不同程度的Overdraw情况,1x、2x、3x和4x分别表示同一像素上同一帧的时间内被绘制了多次,1x就表示一次(最理想情况),4x表示4次(最差的情况),而我们做性能优化时,考虑消除的就是3x和4x。
优化方案
减少布局嵌套
上面提及过,Android中对View的测量和布局绘制时,都是通过对树进行遍历操作的,Google设计嵌套View最多是10层否则会崩溃,当View树的层数过深时会严重影响测量,布局,绘制的速度。
在Android Studio中,有一个很好用的工具能直观的查看我们的UI布局,而不需要一个一个的查看xml文件。只需要点击左上角Tools-Layout Inspector,然后启动APP,就能看到了:

目前Google已经将ConstraintLayout设置为默认的根布局,之前则是RelativeLayout,这些布局的特点就是能用很少的布局层级来约束UI的位置,减少布局层级的深度,降低性能开销。而如果使用LinearLayout这种通常会多一个层级,从而增加开销。
还可以使用抽象标签:
<include>标签,可以将布局中的公共部分提出来,但这个标签并不会对布局层次有什么优化,更多的是让我们能写更少的代码以及在嵌套引用时思路清晰,不用看着一堆<>而烦恼。使用方法:
xml<include layout="@layout/..." />
<merge>标签,可以降低UI层级,但他只能作为xml layout的根节点,常用于替换FramelLayout或者消除父子层次结构中多余的视图组。比如我们在一个垂直结构中引入了一个布局,此时<include>里面的布局如果也是垂直布局就没有意义了,此时我们使用<merge>标签可以排除一个布局插入另外一个布局时产生的多余的ViewGroup。替换
FrameLayout:xml<?xml version="1.0" encoding="utf-8"?> <merge xmlns:android="http://schemas.android.com/apk/res/android" android:layout_width="match_parent" android:layout_height="match_parent" > <TextView android:layout_width="match_parent" android:layout_height="wrap_content" android:text="我是button" /> <Button android:layout_width="match_parent" android:layout_height="wrap_content" android:text="我又是个button" /> </merge>插入布局时消除多余的视图:
xml<LinearLayout android:id="@+id/container" android:layout_width="match_parent" android:layout_height="match_parent" android:orientation="vertical" > <include layout="@layout/layout_merge" /> </LinearLayout>
@layout/layout_merge为上面的layout,显然是垂直排列的,故这里即可取消嵌套无用的垂直LinearLayout。注意,在使用
<merge>标签时,要注意下面几点:
<merge>只能用在XML文件的根元素。- 使用
<merge>标签时,在inflate加载时必须要有父ViewGroup,且attachToRoot参数必须为true。- 不能在
<ViewStub>中使用<merge>标签。
<ViewStub>标签,该标签可以在需要加载的时候才加载不会影响UI初始化的性能。一些我们只有在特定情况才显示的UI就可以用<ViewStub>来优化。与View.Gone不同,<ViewStub>用完后就会清空,而View.Gone则不会被清空释放内存,能被再次调用出来,只是肉眼上的不可见而已。各种不常用的布局文件如进度条、显示错误信息等可以使用标签以减少内存使用量,加快渲染速度。标签是一个不可见的,大小为0的View。故需要有父ViewGroup作为占位。
xml<!-- layout.xml --> <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" android:orientation="vertical" android:layout_width="match_parent" android:layout_height="wrap_content"> <ViewStub android:id="@+id/view_stub" android:layout_width="match_parent" android:layout_height="wrap_content" android:layout="@layout/extra_layout" /> </LinearLayout>在使用时:
kotlinval stub: ViewStub = findViewById(R.id.view_stub) // 在代码中动态加载 ViewStub val inflatedView: View = stub.inflate() // 将 ViewStub 替换为实际的布局
最后,可以减少不必要的背景设置,比如子控件可以使用父控件的背景时,就没必要单独为子控件设置背景。
避免过度绘制
如果我们发现了自己的APP出现了过度绘制的情况,一是可以用XML布局优化来减少过度绘制。主要就是在使用XML布局时,会设置很多背景,我们要尽可能的移除其中的背景。
移除默认的Window背景
在APP中,一般默认的主题都有windowBackGround,比如在Light主题中(默认的Theme.Material3.DayNight.NoActionBar是继承于这个Light主题的):
<style name="Theme.Light">
<item name="isLightTheme">true</item>
<item name="windowBackground">@drawable/screen_background_selector_light</item>
...
</style>这个背景我们在绝大多数情况下都是用不到的,因此我们可以将其移除:
// 方式1:在应用的主题中添加如下的一行属性
<item name="android:windowBackground">@android:color/transparent</item>
<!-- 或者 -->
<item name="android:windowBackground">@null</item>// 方式2:在 BaseActivity 的 onCreate() 方法中使用下面的代码移除
getWindow().setBackgroundDrawable(null);
<!-- 或者 -->
getWindow().setBackgroundDrawableResource(android.R.color.transparent);如果我们要使用
SplashScreen设置启动页时,初始Activity的Theme不能设置windowBackground = transparent!
移除控件中不必要的背景
比如子View的背景和父View的背景是相同的,那么我们可以去除子View/父View的背景,从而避免过度绘制。Rv中,如果Rv的背景和item的背景一致,则item就没有必要设置背景。
自定义View优化
使用clipRect()和quickReject()优化。clipRect()是为canvas设置一个裁剪区域,只有在该区域内才会绘制,而超出这个区域的就不会绘制。比如最常见的抽屉布局:

在左边的抽屉被拉出来后,可以发现并没有被过度绘制,是因为使用了clipRect()将原主布局的显示区域改为除去抽屉遮挡的剩下一部分,所以实际上被抽屉遮挡的主布局并不会被绘制出来。点进DrawerLayout的源码可以看到:
@Override
protected boolean drawChild(Canvas canvas, View child, long drawingTime) {
final int height = getHeight();
final boolean drawingContent = isContentView(child);
int clipLeft = 0, clipRight = getWidth();
//保存当前的canvas绘图状态到保存栈中,方便在后续使用canvas.restoreToCount(restoreCount)恢复回来
final int restoreCount = canvas.save();
if (drawingContent) {
final int childCount = getChildCount();
//遍历DrawerLayout的childView,拿到抽屉布局
for (int i = 0; i < childCount; i++) {
final View v = getChildAt(i);
//如果不是抽屉布局就跳过
if (v == child || v.getVisibility() != VISIBLE
|| !hasOpaqueBackground(v) || !isDrawerView(v)
|| v.getHeight() < height) {
continue;
}
//如果是左抽屉布局
if (checkDrawerViewAbsoluteGravity(v, Gravity.LEFT)) {
final int vright = v.getRight(); //拿到他的右边的距离
if (vright > clipLeft) clipLeft = vright; //如果他右边的距离把之前裁剪的左边距覆盖了,就更新剩余部分左距离
} else {
//如果是右抽屉布局
final int vleft = v.getLeft(); //拿到他左边的距离
if (vleft < clipRight) clipRight = vleft; //更新剩余部分的右边距
}
}
//四个参数分别代表左边,顶部,右边,底部的距离
canvas.clipRect(clipLeft, 0, clipRight, getHeight()); //裁剪出原布局的剩余显示范围,避免过度绘制
}
...
}quickReject()是用来判断和某个矩形相交,使用时如果相交了则可以跳过这一部分的绘制。
耗电优化
耗电优化对于一款APP的优化过程还是比较重要的,我们都知道在看视频时耗电是相对比较快的,此时如果一个视频APP的耗电比另一个视频APP更大,那么我们更愿意选择耗电小的那个APP。
而耗电的原理,简单来说就是用户->软件->硬件->耗电这一系列过程,核心就是软件调用了硬件从而产生耗电,那么这里面有哪些常用硬件是可控的呢?

音视频
在使用音视频时,会涉及到许多硬件,恰好这两个又是我们日常中使用得最多的,所以我们一定要做到当不使用时及时释放资源,也可以注意下面几点:
- 动画等特效是否及时释放
- 检查内存,CPU使用情况
- 帧率不宜过高
- 可以在多个页面间使用共享的播放器实例,减少开销
网络
移动设备连接网络有移动网络,WIFI两种情况,通常情况下,使用移动网络的功耗要远大于WIFI的功耗。
使用移动数据时,消耗有下面三种状态:
- 高功率状态(Full Power):移动网络连接被激活,允许设备以最大传输速率进行操作。
- 低功耗状态(Low Power):此时电量的消耗大约是高功率状态的一半。
- 空闲状态(Standby):此时没有数据传输,电量消耗最小。
三种状态的转化图如下:

在应用中,每次创建一个新的网络连接,网络模块都会转到高功耗状态,然后等待数据传输完成后会转回到低功率状态,这个过程需要五秒(此时仍会保持高功耗状态),最后再转回空闲状态,这个过程需要十二秒。故每次的数据传输都会消耗近20秒的电量。
而WIFI的耗电与包率(每秒发送和接受的包数)和通道率(网速)这两个因素有关,WIFI组件在active状态下有4种模式:低功率,高功率,低传输,高传输。当WIFI组件从低(高)功率开始传输数据时,会短暂的进入低(高)传输状态,传输完毕后就会回到原来的状态。在进行高速传输时,WIFI组件在高传输状态维持时间非常短,而在低速传输时,低传输状态维持时间更短。所以使用移动网络的功耗要远大于WIFI的功耗。
那么我们应该如何优化呢?
- 在WIFI状态下,应尽可能增大每个包的大小(不超过MTU)并降低发包的频率。
如果发包的频率过大,则会导致每次都会进入传输状态,而这个状态每次都会增加开销,且如果过于频繁则很难回到低功耗状态,会造成大量电费浪费。
MTU,最大传输单元,如果超出了MTU,IP层会把数据分片,会导致多余的开销。
- 在移动网络下,最好能批量执行网路请求,使得状态能尽量多的保持在空闲状态,减少不必要的电量消耗。
- 使用效率高的数据解析方式,比如JSON。
- 压缩数据格式,比如GZIP压缩(okhttp默认使用了GZIP压缩),经过压缩的数据所需传输时间会更少,从而减少耗电。
CPU
CPU是智能移动设备的核心,也是最繁忙的硬件模块,要减少CPU的耗电,就要使CPU保持在最合适的状态。CPU被高频使用有下面几个原因:
- 程序运算复杂(如高精度),导致CPU满负荷运载。缩短代码产生指令运行的时间,就能减少该APP占整个系统耗电的一个程度。
而浮点运算比整数运算更消耗时间,进而增加耗电,故在编写代码时应尽量减少浮点运算(除法变乘法,善用位运算)。
- 线程短时间内无规则强占CPU资源。
- WakeLock唤醒。在一些场景中,即使我们不使用屏幕,使手机处于待机状态,有时一些应用仍需不断更新界面,检查是否有新的数据,此时就会使用PowerManager.WakeLock来保持CPU工作,可以使手机处于唤醒状态。PowerManager是对手机设备电源进行管理,而只要应用中存在WakeLock,就能通过一定办法达到对应电源的管理目的,防止进入休眠。
网络优化
网络这方面的影响对用户比较直观,比如流量的消耗以及网路请求的等待。
优化方案
使用网络缓存
我们可以对以后可能会经常反复用到的东西在第一次加载后保存到本地,不仅能使下次加载更快还能减少重复的网络请求带来的不必要的流量开销。
限制访问次数
可以通过限制用户对网络请求的访问次数减少流量消耗(比如对一个按钮在按下后,在一定时间内不能再次点击)。
安装包优化
顾名思义,就是要减少安装包的大小,用户长时间使用后,会产生大量用户数据,留给APP的安装空间就更少了。
优化方案
- 清理无用资源。在Android Studio中【Refactor】->【Remove Unused Resources..】,选择【preview】可以查看无用的资源代码。
- Android Lint。在【Code】 -> 【Inspect Code】中,可以对代码进行检查:

检查完成后如下图:

可以看到这里Lint问题有很多种类:
Correctness 不够完美的编码,比如硬编码、使用过时 API 等Performance 对性能有影响的编码,比如:静态引用,循环引用等Internationalization 国际化,直接使用汉字,没有使用资源引用等Security 不安全的编码,比如在 WebView 中允许使用 JavaScriptInterface 等Usability 可用的,有更好的替换的 比如排版、图标格式建议.png格式 等Accessibility 辅助选项,比如ImageView的contentDescription往往建议在属性中定义 等
更详细的内容可以参考这篇博客:Android性能优化之 Android Lint
- 使用shrinkResources
minifyEnabled true开启混淆后也可以减少APK体积,还有个是shrinkResources true。前者是用来删除无用的代码,后者则是用来删除无用的资源和文件。
只有当
minifyEnabled true生效时,shrinkResources true才会生效。那么如何保留我们并不想让他删除的资源呢?新增一个res/raw/keep.xml文件:xml<?xml version="1.0" encoding="utf-8"?> <resources xmlns:tools="http://schemas.android.com/tools" tools:keep="@drawable/xxxx,@layout/xxxxx"/>
- 资源压缩
APP中,可能会使用到很多的图片,而每张图片都是很占资源的,因此我们可以从这些图片的压缩上下手:
(1)使用压缩工具对图片进行压缩 (2)尽量将图片都用Webp格式的,其次是JPG格式,再是PNG格式 (3)使用SVG,矢量图能比位图节约30%~40%的空间 (4)尽量不要在项目中使用帧动画 (5)重用Bitmap,不使用了记得回收
内存优化
每个APP在运行过程中所能拿到的内存是固定的,并且移动设备的内存相对于PC很小,所以合理的管理内存显得就非常重要了。
关于内存的一些基础
Android最新系统都运行在ART虚拟机上,基于Linux内核实现,而Linux希望尽可能多的利用内存,Android则也继承了这个特点。
而与Linux不同,Android侧重于尽可能多的缓存进程从而提高响应和切换速度,意味着在内存足够的情况下会尽可能的保持应用的进程,直到内存不足时才会根据进程优先级等条件回收进程。这些长时间保持的应用进程不仅不会影响系统整体的速度,还会在用户再次激活这些进程时加快其响应速度。
Java引用类型
- 强引用(StrongReference)。强引用是Java中最常用的引用类型,平常默认创建的也是强引用。当一个对象为强引用类型时,永远不会被垃圾回收,只有在程序结束或者对象被赋值为
null时才会释放强引用。 - 软引用(SoftReference)。当JVM内存充足时,不会回收软引用对象。而如果内存不足时,可能会被回收(GC并不一定会回收软引用对象)。
SoftReference<Object> softRef = new SoftReference<>(new Object());- 弱引用(WeakReference)。GC只要发现弱引用对象,无论内存是否充足,都会立即回收。
WeakReference<Object> weakRef = new WeakReference<>(new Object());- 虚引用(PhantomReference)。不能通过
get()获取对象,只能用于跟踪即将对被引用对象进行的收集,相当于对象被回收前的“通知”机制,必须与ReferenceQueue类联合使用。
Java内存模型
JVM将内存分为了几部分,借用网上一张图:

- 方法区:存储类信息,常量,静态变量,所有线程共享区。
- 堆区:内存最大的区域,所有线程创建的对象都会在这个区里面分配内存,而在虚拟机栈中分配的实际上是指向堆的一个引用,GC主要是对这部分区域进行处理,也是内存泄漏的主要发生区域,所有线程共享区。
- 虚拟机栈:存储当前的局部变量表,操作数栈等数据,线程独有区,也就是每个线程在运行时都有一个独立的虚拟机栈。
当每个java方法执行时,java虚拟机会同步创建一个栈帧(stack frame),用于存储该方法的局部变量,操作数栈(存储方法执行中的临时数据),动态链接(保存对常量池的引用),方法出口(调用完成后的返回位置)。当一个方法被调用完毕后就会被弹出并返回给调用者。
内存溢出Java.lang.stackOverflowError 栈内存溢出就是因为虚拟机栈中栈帧过多或每个栈帧占用内存过大。
- 本地方法栈:与虚拟机栈发挥作用类似,只不过这个是用于native层。
- 程序计数器:存储当前线程执行目标方法到哪行,也是线程私有的。执行java方法时,计数器记录虚拟机字节码指令的地址。执行native方法时,计数器为空。
GC垃圾回收
使用下面两种方法可以判断哪些是垃圾:
1.引用计数法
为每一个对象添加一个引用计数器,当这个对象的引用被创建时,计数器+1;当这个引用不在指向这个对象时,计数器-1。如果一个对象的引用计数器为0了,就说明不再被任何其他对象引用,GC就可以进行回收了。
虽然这样会占用一些其他内存进行计数但原理简单,也比较有效率,但是却无法解决循环引用的问题,比如A引用了B,B引用了A,这时A和B永远也不会被回收,容易造成内存泄漏。
2.可达性分析算法
基本思路是通过“GC Roots”的根对象作为起始节点集,根据引用关系向下搜索,走过的路径被称作“引用链”。如果一个对象没有被任何引用链相连,则说明这个对象不可达,则证明对象是垃圾,GC可以进行回收。
GC Roots主要有虚拟机栈中的局部变量,活动的线程,静态变量,常量池等。
Java虚拟机内存回收算法
标记-清除
先标记所有可回收的对象,再统一回收掉被标记的对象。同时会产生不连续的内存碎片,这会导致后面如果需要分配较大对象时,找不到连续的内存,而不得不再次触发GC。

复制-清除
先将内存划分为两块,每次只使用其中的一块,这块用完时,就将存活的对象转移到另一半上面,然后将已使用的全部清理就好了,就不用考虑内存碎片的问题,非常简单。缺点就是需要两倍空间。



标记-整理
简单来说就是先用标记-清理算法,然后将内存从后往前移动,清除内存碎片,同时更新对象的指针。
分代回收策略
大概就是前面三种方法的实际应用,新生代,老年代,永久代,大部分虚拟机厂商使用这个方式进行GC。
新生代:朝生夕灭,存活时间短。eg:某一个方法的局部变量,循环内的临时变量等等。
老年代:生存时间长,但总会死亡。eg:缓存对象,数据库连接对象,单例对象等等。
永久代:几乎一直不灭。eg:String池中的对象,加载过的类信息。
Android内存回收机制
在Android高系统版本中,针对Heap空间有一个Generational Heap Memory的模型。
Heap空间,即堆空间,用来存放所有对象实例的一个内存区域。
他将整个内存分为了三个区域:
1.Young Generation,由一个Eden区和两个Survivor区组成:
程序中生成的大部分新的对象都会放在Eden区。若Eden区内存满了后,会将仍然存活的对象放到Survivor区。同理,当Survivor区满了后,会将Survivor存活的对象放到另一个Survivor区。当这个Survivor区也满了后,则会将存活的对象复制到Old Generation。
2.Old Generation,老年区说明不易被回收。
3.Permanent Generation,存放静态类和静态方法
LMK机制
全称Low Memory Killer,是一种根据内存阈值级别触发的内存回收机制,在系统可用内存较低时,就会触发杀死进程的一种策略。而在选择要杀死的进程时,系统会根据其运行状态做出判断,主要依据是四大组件。会从重要性由低到高依次删除。
Android中APP的重要层次一共分为五层:前台进程,可见进程,服务进程,后台进程,空进程。每个进程的优先级不是固定的,比如一个前台进程进入了后台,那么AMS(Activity Manager Service)就会发出进程优先级更新的请求。
Android后台杀死:LowMemoryKiller原理
内存抖动
内存抖动的出现是因为有大量对象进入JVM的新生区导致的,内存波动特别大,成锯齿状。内存抖动伴随着频繁的GC,这会大量占用UI线程和CPU资源,而频繁的GC会导致STW,导致APP卡顿,性能下降。
GC频繁出现的原因:瞬间产生的大量对象会严重挤占Young Generation的内存空间,当超过上限时,就会触发GC。
STW(Stop The World),GC的回收方式有很多种,但无论哪种回收方式都会暂停应用程序中的线程,等待垃圾回收完成,以保证回收过程中的内存的统一性和安全性,因为在GC的回收过程中,会检查对象的引用性,而如果不暂停线程,就可能会导致对象的引用性改变,从而导致GC的错误回收。
如何检测内存抖动
AS有自带的内存抖动的工具——Memory Monitor。左边工具栏有个Profiler,然后选择你的手机和APP,分析内存消耗。可以看到这里主要是对Java/Kotlin对象进行分析。


就会有各个语言占用内存情况,如果被频繁GC会出现垃圾桶的形状,而下面的则代表了各个对象内存分配情况,我们可以进行查看和跳转:

一般发生内存抖动的现象都是由于频繁创建java/kotlin对象导致的,这里由于没有出现内存抖动,就不做演示,一般是进行跳转后根据指示的代码位置进行对症下药就好了。比如下面这个代码:
fun concatenateStrings(strings: List<String>): String {
var result = ""
for (str in strings) {
result += str // 每次拼接都会创建一个新的 String 对象
}
return result
}那么由于这里每次都会创建一个新的对象,肯定会导致内存抖动,我们只需要换成StringBuilder就可以了:
fun concatenateStrings(strings: List<String>): String {
val builder = StringBuilder()
for (str in strings) {
builder.append(str) // 使用 StringBuilder 减少对象分配
}
return builder.toString()
}这样就能解决内存抖动。
内存抖动的优化
1.避免频繁的创建临时对象。比如上面提到的字符串拼接。
2.对象复用。频繁使用类似对象,可通过对象池(如 SparseArray、ObjectPool)实现复用。
3.在自定义View中的onDraw方法内不要创建对象,提前缓存Paint或Path。
4.减少重复分配和大块内存使用
还有一些不太常用的就遇到了再解决吧
对象池
对象池,用来存储需要大量复用的对象,这里借用网上一张图:

- Pool代表的就是对象池。
- 第二步操作就是代表从对象池中取出对象,进行“租借”。
- 第三步就是用取出的对象完成一些任务/操作。
- 第四步就是用完后将对象还到对象池。
对于上面提到的SparseArray,是Android提供的一个高效的map实现,用于存储对象,小的对象池可以直接用SparseArray实现:
class ImagePool {
private val pool = SparseArray<Bitmap>()
// 从池中借用图片
fun borrowImage(key: Int): Bitmap? {
return pool.get(key)
}
// 归还图片到池中
fun returnImage(key: Int, bitmap: Bitmap) {
pool.put(key, bitmap)
}
}关于Pools的原理可以去看这篇文章:Android 对象池的原理和使用
内存泄漏
内存泄漏,就是一个本该被回收的对象却无法被GC回收,造成了系统内存的浪费,最终可能导致应用OOM或者界面卡顿。
从上面提到过的GC垃圾回收可知,我们判断一个对象是否该被GC回收是通过判断这个对象是否“可达”。而内存泄漏的本质就是长生命周期持有短生命周期的引用,导致短生命周期无法被GC回收,最典型和最常用的短生命周期对象是Activity和Fragment,它们泄漏会直接导致内存无法释放,引起性能问题。
常见内存泄漏场景
1.资源未释放
- BroadcastReceiver没有反注册或RxJava没取消订阅。这会导致回调对象被系统或者第三方库持有,形成长生命周期引用。
- Cursor没有及时关闭
- 流没有关闭,Bitmap没有进行回收,这些系统资源未释放会导致GC无法回收(因为这些对象在“引用链”上)
2.静态变量存储大数据对象
上面提到过,静态变量会储存在方法区里面,而方法区是一个生命周期长,不易被回收的区域,那么如果静态变量存储的数据内存占用比较大,就很容易内存泄漏并出现OOM。
3.单例
如果在单例中使用了Activity的context,就会造成内存泄漏。解决办法:可以使用Application的context,也可以将context用弱引用包装,获取时如果获取不到则说明被回收掉了,则返回一个新的context。
4.非静态内部类的静态实例
静态内部类和非静态内部类的区别:非静态内部类可以访问外部类的所有属性,而静态内部类只能访问外部类的静态属性(companion object)。且非静态内部类和外部类是绑定的,而静态内部类则不依赖于外部类,即使外部类被回收了,静态内部类也不会被回收。
而非静态内部类需要创建一个外部对象才能创建内部,因为非静态内部类需要访问外部类的成员,故一定需要一个实例,而这个实例的创建往往是隐式的。
所以,我么可以发现,如果非静态内部类的静态实例会一直持有外部类的实例(隐式持有,因为他本身是一个非静态类),而静态实例会与类的生命周期绑定,即使外部类被销毁,静态实例也会持有外部的引用。那么如果这个实例是activity的话,就相当于长生命周期持有短生命周期的引用,则可能导致内存泄露。
5.Handler内存泄漏
我们经常使用Handler进行线程切换,非静态内部类Handler的target会持有外部activity的引用,Message持有Handler的引用,而message又被MessageQueue引用,MessageQueue又会被Looper引用,Looper又被ThreadLocal引用,而ThreadLocal可以为每一个线程维护一个数据,属于线程栈变量,即GC Roots,那么这个Message就在这条“引用链”上而不会被GC回收,但如果Message是个延时消息,而在这个过程中Activity被销毁,那么他就不能被回收且一直占用着内存,导致内存泄漏。
那么如何解决这个内存泄漏问题呢?一是可以使用静态类(因为静态内部类不会持有外部的引用的),并使用WeakReference持有Activity,或者在onDestroy()时手动清除所有message:
class MainActivity : AppCompatActivity() {
// 静态Handler,避免隐式持有Activity
private val handler = MyHandler(this)
private class MyHandler(activity: MainActivity) : Handler(Looper.getMainLooper()) {
private val activityRef = WeakReference(activity) // 弱引用
override fun handleMessage(msg: Message) {
val activity = activityRef.get()
activity?.let {
// 仅当Activity存活时处理消息
}
}
}
override fun onDestroy() {
super.onDestroy()
handler.removeCallbacksAndMessages(null) // 移除所有消息
}
}6.WebView
一般情况下,在应用中只要使用一次 Webview,它占用的内存就不会被释放,解决方案:我们可以为WebView开启一个独立的进程,使用AIDL(Android Interface Definition Language)与应用的主进程进行通信,WebView所在的进程可以根据业务的需要选择合适的时机进行销毁,达到正常释放内存的目的。
这里是在网上看到的,WebView内部的一些线程会持有activity的引用,导致无法释放从而造成内存泄漏,看网上的说法是不要用xml构建,而是用代码new出来,然后将activity使用弱引用的方式传进去,然后在onDestroy()方法中先从父控件中移除WebView,再销毁WebView。但是有的又说WebView基本不会造成内存泄漏,可以用xml创建,onDestroy()时stopLoading+destroy就好了。而AIDL方法感觉就是通过Service,来开启新的独立进程来使用WebView。
我自己目前太菜了,能力有限,具体的也研究不出来😭😭😭,故在这里留个坑(勿喷)。
一些参考文章(不知道参考价值大不大):
如何分析内存泄漏
Android Studio Profiler
在之前内存抖动中简单说了下这个分析工具,这里再详细说一下:

内存信息框:
- 1.Others:系统不确定归类到哪一类的内存
- 2.Code:存储代码和资源的信息,如dex字节码,经过优化或者编译后逇dex代码,.so库和字体等
- 3.Statck:原生堆栈和 Java 堆栈使用的内存。这通常与您的应用运行多少线程有关。
- 4.Graphics:图形缓冲区队列为向屏幕显示像素(包括 GL 表面、GL 纹理等等)所使用的内存。(请注意,这是与 CPU 共享的内存,不是 GPU 专用内存。)
- 5.Native:从 C 或 C++ 代码分配的对象的内存。
- 6.Java:从 Java 或 Kotlin 代码分配的对象的内存。
- 7.Allocated:您的应用分配的 Java/Kotlin 对象数。此数字没有计入 C 或 C++ 中分配的对象
上面的图就表示了每个时间阶段的内存分配情况,有垃圾桶的地方表示此时正在频繁GC。
而我们应重点关注内存使用的分析。应点击Analyze Memory Usage(Heap Dump):

而下图则是分析后的HeapDump文件,展示了堆内存状态,包括所有对象的类型,数量和引用关系。

首先第一个View app heap,这是需要检查的堆,有下面几个选项:
View all heaps: 查看所有的heap情况。
View app heap: 应用在其中分配内存的主堆
View image heap: 系统启动映像,包含启动期间预加载的类,此处的分配确保绝不会移动或消失。
View zygote heap: 写时复制堆,其中的应用进程是从Android系统中派生的。
第二个Arrange by class,是选择怎样排序,有下面几个选项:
- Arrange by class: 根据类名称进行分组,这是默认的排序。
- Arrange by package: 根据软件包名称对所有分配进行分组。
- Arrange by callstack: 将所有分配分组到其对应的调用堆栈。
第三个是选择显示哪些类,有下面几个选项:
- Show all classes: 展示所有Class类(包括系统类),这是默认值
- Show activity/fragment Leaks:展示泄露的activity/fragment。
- Show project class:展示项目的Class类。
第四个是可以搜索你要查找的类,比如你怀疑某个类存在内存泄漏。
第五个这里左边表示一共有多少类,右边表示asp提供给我们的内存泄露情况
下面一行表示的是当前设备内存使用的具体情况
- Allocations: 当前内存中类对象个数
- Native Size: 此类型对象使用的原生内存总量。
只有在使用 Android 7.0 及更高版本时,才会看到此列 您会在此处看到采用 Java 分配的某些对象的内存,因为 Android 对某些框架类(如 Bitmap)使用原生内存。
- Shallow Size: 此对象本身占有的内存。
- Retained Size: 此对象引用链上的所有对象的总内存使用
那么我们如何查看内存泄漏的引用链呢?我们点到asp提供给我们的内存泄漏情况,这里以一个Fragment为例:

我们点进可能泄漏的类型,然后点击详细列表的“Reference”,勾上“Show nearest GC root only”,就可以显示当前泄漏对象的引用链。
我们详细看一下引用链:

我们可以发现,这是因为在这个VP2里面的这个fragment,在使用Handler进行网络请求时,持有了外部activity的引用,导致了内存泄漏(具体原因看上面分析)。
这样我们就能发现内存泄漏的原因了。
MAT
我们可以借助ASP导出的heap文件结合MAT分析,但这个做法效率低也很麻烦,有兴趣的可以读下这篇参考文章:
LeakCanary
LeakCanary是Square公司为Android开发者提供的一款基于MAT的自动检测内存泄漏的工具,使用高校,方法也很简单。
使用方式
首先导入依赖:
debugImplementation 'com.squareup.leakcanary:leakcanary-android:2.9.1'然后我们运行项目,就会发现多了一个小黄鸟APP:

然后我们在APP中到处点,如果出现了内存泄漏,那么APP就会给手机发通知,然后开始下载文件并进行分析,分析完成后又给你一个通知:

然后我们点进小黄鸟APP,就能看到为我们生成的发生内存泄漏的引用树:
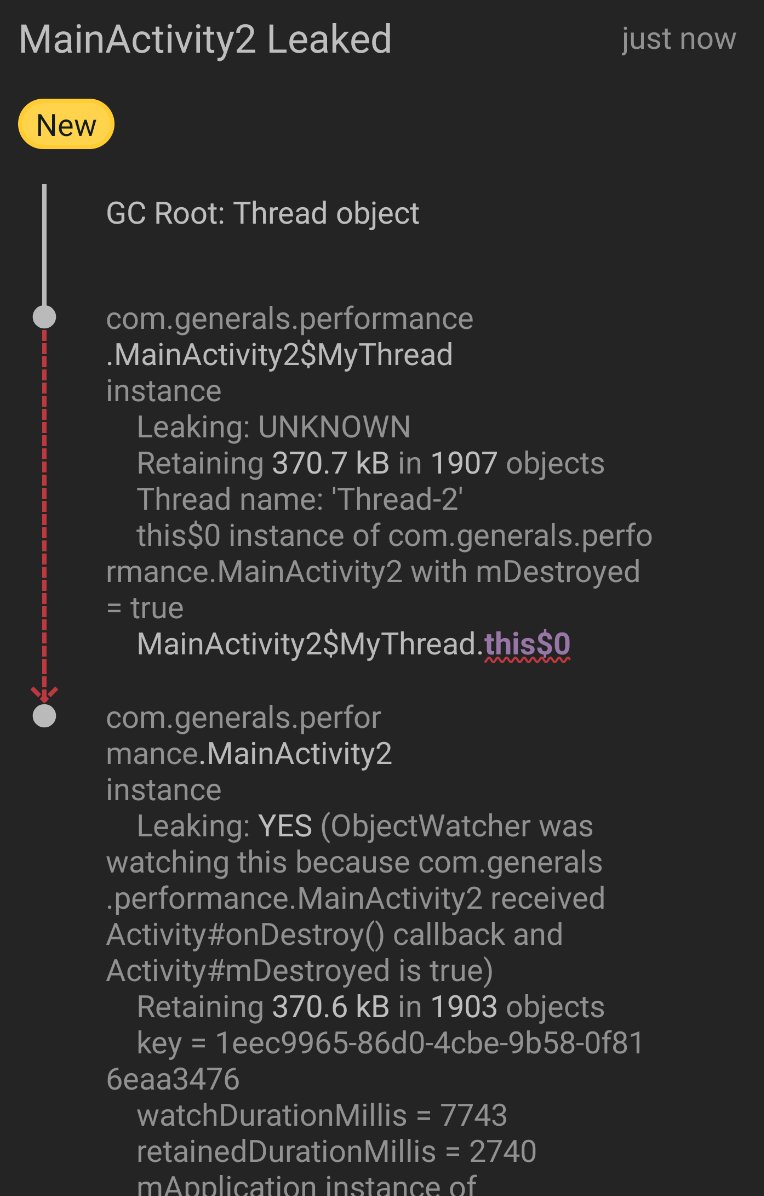
这里我们观察到是因为MyThread类持有了Activity的引用导致了内存泄漏,然后我们查看代码:
class MainActivity2 : AppCompatActivity() {
@SuppressLint("MissingInflatedId")
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main2)
MyThread().start()
findViewById<Button>(R.id.btn_click2).setOnClickListener {
// Thread.sleep(30000)
finish()
}
}
inner class MyThread : Thread() {
override fun run() {
sleep(60*1000)
}
}
}发现确实是这个问题。
源码分析
简单来说,LeakCanary的一个简单实现思路就是将弱引用和引用队列ReferenceQueue进行关联,如果弱引用的引用对象被回收,JVM就会把这个弱引用加入到相关联的引用队列中,这样就能检测一个对象是否被GC回收。我们这里模拟一下大概的实现:
fun main() {
var obj: Any? = Object()
val referenceQueue = ReferenceQueue<Any?>()
val weakReference = WeakReference<Any?>(obj,referenceQueue) //将obj与弱引用关联,再将弱引用与引用队列关联
var ref = referenceQueue.poll() //此时未进行回收
println("before:$ref") //输出引用队列
obj = null //将他置空,与Object()的引用断开
System.gc() //进行垃圾回收
Thread.sleep(2000)
ref = referenceQueue.poll() //此时被回收后,obj会添加到引用队列中
println("after:$ref") //输出引用队列
}
可以看到符合我们的分析。
接下来我们看LeakCanary的具体源码。
我们可以发现,我们只需要导入LeakCanary库就好了,并不需要进行设置他就可以自动初始化。这是如何实现的呢?实际上他是通过ContentProvider,实现的自动初始化。而ContentProvider的onCreate()方法是在Application.onCreate()前面执行的,我们看LeakCanary的清单文件:
<?xml version="1.0" encoding="utf-8"?>
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.squareup.leakcanary.objectwatcher" >
<uses-sdk android:minSdkVersion="14" />
<application>
<provider
android:name="leakcanary.internal.MainProcessAppWatcherInstaller"
android:authorities="${applicationId}.leakcanary-installer"
android:enabled="@bool/leak_canary_watcher_auto_install"
android:exported="false" />
</application>
</manifest>我们可以看到,在清单文件中也是定义了一个ContentProvider,而一个APP只会有一个清单文件,在构建应用时,Gradle会将全部清单文件按照一定优先级进行合并。然后我们看他的MainProcessAppWatcherInstaller类:
internal class MainProcessAppWatcherInstaller : ContentProvider() {
override fun onCreate(): Boolean {
val application = context!!.applicationContext as Application
AppWatcher.manualInstall(application) //在onCreate()中初始化AppWatcher
return true
}
...
}然后点进去AppWatcher.manualInstall(application)方法:
@JvmOverloads
fun manualInstall(
application: Application,
retainedDelayMillis: Long = TimeUnit.SECONDS.toMillis(5), //对检测对象延迟5秒检测
watchersToInstall: List<InstallableWatcher> = appDefaultWatchers(application)
) {
checkMainThread()
if (isInstalled) {
throw IllegalStateException(
"AppWatcher already installed, see exception cause for prior install call", installCause
)
}
check(retainedDelayMillis >= 0) {
"retainedDelayMillis $retainedDelayMillis must be at least 0 ms"
}
this.retainedDelayMillis = retainedDelayMillis
if (application.isDebuggableBuild) {
LogcatSharkLog.install() //日志的初始化
}
// 核心组件
LeakCanaryDelegate.loadLeakCanary(application)
//对每一个检测器进行初始化
watchersToInstall.forEach {
it.install()
}
// Only install after we're fully done with init.
installCause = RuntimeException("manualInstall() first called here")
}看他的watchersToInstall参数,提供了一个默认值:appDefaultWatchers(application),我们点进去看:
fun appDefaultWatchers(
application: Application,
reachabilityWatcher: ReachabilityWatcher = objectWatcher
): List<InstallableWatcher> {
return listOf(
ActivityWatcher(application, reachabilityWatcher), //对Activity的检测器
FragmentAndViewModelWatcher(application, reachabilityWatcher), //对Fragment和Viewmodel的检测器
RootViewWatcher(reachabilityWatcher), //对RootView的检测器
ServiceWatcher(reachabilityWatcher) //对Service的检测器
)
}我们发现,他为我们生成了四个默认的检测器,传入objectWatcher和application然后我们依次来看这几个检测器:
ActivityWatcher
class ActivityWatcher(
private val application: Application,
private val reachabilityWatcher: ReachabilityWatcher
) : InstallableWatcher {
private val lifecycleCallbacks =
object : Application.ActivityLifecycleCallbacks by noOpDelegate() {
override fun onActivityDestroyed(activity: Activity) {
reachabilityWatcher.expectWeaklyReachable(
activity, "${activity::class.java.name} received Activity#onDestroy() callback"
)
}
}
override fun install() {
application.registerActivityLifecycleCallbacks(lifecycleCallbacks) //注册Activity生命周期的监听
}
override fun uninstall() {
application.unregisterActivityLifecycleCallbacks(lifecycleCallbacks)
}
}可以看到,install()方法是注册了Activity生命周期的监听,然后在activity快Destroy时调用了Application.ActivityLifecycleCallbacks的onActivityDestroyed方法,然后调用了reachabilityWatcher的expectWeaklyReachable方法,这个reachabilityWatcher就是我们传进来的,我们回头发现传进来的是objectWatcher,我们点进objectWatcher看:
val objectWatcher = ObjectWatcher(
clock = { SystemClock.uptimeMillis() },
checkRetainedExecutor = {
// ObjectWatcher被AppWatcher用来检测保留的对象。仅当isInstalled为true时设置。
check(isInstalled) {
"AppWatcher not installed"
}
mainHandler.postDelayed(it, retainedDelayMillis)
},
isEnabled = { true }
)我们发现这里clock传入了一个时间,第二个参数是一个Executor,这里提交了一个任务给主线程的Handler延时处理,retainedDelayMillis就是在APPWatcher中设置的默认5秒,然后再看ObjectWatcher对expectWeaklyReachable的实现:
@Synchronized override fun expectWeaklyReachable(
watchedObject: Any,
description: String
) {
if (!isEnabled()) {
return
}
removeWeaklyReachableObjects() //清空观察区里面被回收的对象
//生成UUID Key,便于从列表中取出相应的引用
val key = UUID.randomUUID()
.toString()
val watchUptimeMillis = clock.uptimeMillis()
//这里的KeyedWeakReference是弱引用的一个包装类,将观察对象进行弱引用,并且与引用队列关联
val reference =
KeyedWeakReference(watchedObject, key, description, watchUptimeMillis, queue)
SharkLog.d {
"Watching " +
(if (watchedObject is Class<*>) watchedObject.toString() else "instance of ${watchedObject.javaClass.name}") +
(if (description.isNotEmpty()) " ($description)" else "") +
" with key $key"
}
//在观察列表中登记
watchedObjects[key] = reference
//开启子线程检测对象是否关联
checkRetainedExecutor.execute {
moveToRetained(key)
}
}与之前相同,将观察对象进行弱引用,并且与引用队列关联,只有当弱引用的引用对象被回收时,就会把这个引用加到引用队列中,不过这里没有用列表获取泄漏对象,而是直接进行回调通知,在每次观测前清除已经被回收的对象。我们看他是如何清除已经回收的对象的:
private fun removeWeaklyReachableObjects() {
// WeakReferences are enqueued as soon as the object to which they point to becomes weakly
// reachable. This is before finalization or garbage collection has actually happened.
var ref: KeyedWeakReference?
do {
ref = queue.poll() as KeyedWeakReference?
if (ref != null) {
watchedObjects.remove(ref.key)
}
} while (ref != null)
}很好理解,就是不断从引用队列queue中取出数据,如果不为空,说明已经被回收,没有发生泄漏,将其移除(这里就是用的之前生成的唯一UUID来检索)。
我们再来看MoveToRetained方法:
@Synchronized private fun moveToRetained(key: String) {
removeWeaklyReachableObjects()
val retainedRef = watchedObjects[key] //通过唯一的UUID取出观察对象
if (retainedRef != null) {
retainedRef.retainedUptimeMillis = clock.uptimeMillis() //这个是关联对象被认为保留的时间
// 责任链模式,会在后面的核心组件里面设置
onObjectRetainedListeners.forEach { it.onObjectRetained() }
}
}如果我们取出的观察对象不为空,那么可能发生了内存泄漏,我们就记录下时间,然后回调监听。
FragmentAndViewModelWatcher
class FragmentAndViewModelWatcher(
private val application: Application,
private val reachabilityWatcher: ReachabilityWatcher
) : InstallableWatcher {
private val fragmentDestroyWatchers: List<(Activity) -> Unit> = run {
val fragmentDestroyWatchers = mutableListOf<(Activity) -> Unit>()
if (SDK_INT >= O) {
fragmentDestroyWatchers.add(
AndroidOFragmentDestroyWatcher(reachabilityWatcher)
)
}
// AndroidX版本
getWatcherIfAvailable(
ANDROIDX_FRAGMENT_CLASS_NAME,
ANDROIDX_FRAGMENT_DESTROY_WATCHER_CLASS_NAME,
reachabilityWatcher
)?.let {
fragmentDestroyWatchers.add(it)
}
// Android老版本
getWatcherIfAvailable(
ANDROID_SUPPORT_FRAGMENT_CLASS_NAME,
ANDROID_SUPPORT_FRAGMENT_DESTROY_WATCHER_CLASS_NAME,
reachabilityWatcher
)?.let {
fragmentDestroyWatchers.add(it)
}
fragmentDestroyWatchers
}
private val lifecycleCallbacks =
object : Application.ActivityLifecycleCallbacks by noOpDelegate() {
override fun onActivityCreated(
activity: Activity,
savedInstanceState: Bundle?
) {
// 对不同版本的FragmentDestroyWatcher进行监听注册
for (watcher in fragmentDestroyWatchers) {
watcher(activity)
}
}
}
override fun install() {
application.registerActivityLifecycleCallbacks(lifecycleCallbacks)
}
override fun uninstall() {
application.unregisterActivityLifecycleCallbacks(lifecycleCallbacks)
}
...
}这里同样是给activity注册监听,然后遍历fragmentWatcher并设置监听,我们重点看看AndroidX版本的FragmentWatcher:
companion object {
private const val ANDROIDX_FRAGMENT_CLASS_NAME = "androidx.fragment.app.Fragment"
private const val ANDROIDX_FRAGMENT_DESTROY_WATCHER_CLASS_NAME =
"leakcanary.internal.AndroidXFragmentDestroyWatcher"
...
}这里我们去看看AndroidXFragmentDestroyWatcher这个类:
internal class AndroidXFragmentDestroyWatcher(
private val reachabilityWatcher: ReachabilityWatcher
) : (Activity) -> Unit {
private val fragmentLifecycleCallbacks = object : FragmentManager.FragmentLifecycleCallbacks() {
override fun onFragmentCreated(
fm: FragmentManager,
fragment: Fragment,
savedInstanceState: Bundle?
) {
// 对ViewModel的一些监听
ViewModelClearedWatcher.install(fragment, reachabilityWatcher)
}
override fun onFragmentViewDestroyed(
fm: FragmentManager,
fragment: Fragment
) {
val view = fragment.view
if (view != null) {
// 对View泄漏的回调
reachabilityWatcher.expectWeaklyReachable(
view, "${fragment::class.java.name} received Fragment#onDestroyView() callback " +
"(references to its views should be cleared to prevent leaks)"
)
}
}
override fun onFragmentDestroyed(
fm: FragmentManager,
fragment: Fragment
) {
// 这里和activityWatcher差不多,不多解释了
reachabilityWatcher.expectWeaklyReachable(
fragment, "${fragment::class.java.name} received Fragment#onDestroy() callback"
)
}
}
override fun invoke(activity: Activity) {
if (activity is FragmentActivity) {
val supportFragmentManager = activity.supportFragmentManager
// 通过FragmentManager监听Fragment生命周期
supportFragmentManager.registerFragmentLifecycleCallbacks(fragmentLifecycleCallbacks, true)
// 初始化ViewModel
ViewModelClearedWatcher.install(activity, reachabilityWatcher)
}
}
}这里有个invoke的用法,invoke是一个高阶函数的用法,作为(Actrivity) -> Unit的实现,他能让对象变成函数来调用,这里就实现了invoke函数,就能用下面这种形式来调用:
kotlinval watcher = AndroidXFragmentDestroyWatcher(reachabilityWatcher) watcher(activity) // 相当于调用 invoke 方法
我们一步步来,先看看怎样对ViewModel监听的:
internal class ViewModelClearedWatcher(
storeOwner: ViewModelStoreOwner,
private val reachabilityWatcher: ReachabilityWatcher
) : ViewModel() {
// We could call ViewModelStore#keys with a package spy in androidx.lifecycle instead,
// however that was added in 2.1.0 and we support AndroidX first stable release. viewmodel-2.0.0
// does not have ViewModelStore#keys. All versions currently have the mMap field.
private val viewModelMap: Map<String, ViewModel>? = try {
// 通过反射获取ViewModelStore
val mMapField = ViewModelStore::class.java.getDeclaredField("mMap")
mMapField.isAccessible = true
@Suppress("UNCHECKED_CAST")
mMapField[storeOwner.viewModelStore] as Map<String, ViewModel>
} catch (ignored: Exception) {
null
}
override fun onCleared() {
// 当ViewModel销毁时,意味着viewModelStore里的其他ViewModel也会被销毁
viewModelMap?.values?.forEach { viewModel ->
reachabilityWatcher.expectWeaklyReachable(
viewModel, "${viewModel::class.java.name} received ViewModel#onCleared() callback"
)
}
}
companion object {
fun install(
storeOwner: ViewModelStoreOwner,
reachabilityWatcher: ReachabilityWatcher
) {
// 将自己插入viewModelStore来监控通一宿主的viewmodel
val provider = ViewModelProvider(storeOwner, object : Factory {
@Suppress("UNCHECKED_CAST")
override fun <T : ViewModel?> create(modelClass: Class<T>): T =
ViewModelClearedWatcher(storeOwner, reachabilityWatcher) as T
})
provider.get(ViewModelClearedWatcher::class.java)
}
}
}我们看到这个类居然继承了ViewModel(),然后把自己插入viewModelStore中以达到监听的目的。
简单解释一下,viewModel是与activity/fragment绑定的,而
ViewModelStore是一个容器,用于存储与Activity或Fragment相关的所有ViewModel对象。每个Activity或Fragment都会有一个与之关联的ViewModelStore,而我们用的ViewModelProvider就是通过ViewModelStore来访问和存储ViewModel的。当viewModel被销毁时,通常是activity/fragment被销毁,此时意味着ViewModelStore也被销毁了,故其下所有viewModel也会被销毁。更具体的就不知道了。
RootViewWatcher
RootView也是可能出现内存泄漏的,比如自定义了一个Toast弹窗,包含了一个xml布局,此时我将Toast声明成静态方法,然后当弹窗关闭后,肯定会发生内存泄漏,此时LeakCanary提示你就是RootView发生了内存泄漏。
class RootViewWatcher(
private val reachabilityWatcher: ReachabilityWatcher
) : InstallableWatcher {
private val listener = OnRootViewAddedListener { rootView ->
val trackDetached = when(rootView.windowType) {
PHONE_WINDOW -> {
// 拿到当前窗口的回调对象
when (rootView.phoneWindow?.callback?.wrappedCallback) {
// Activities are already tracked by ActivityWatcher
is Activity -> false
is Dialog -> {
// Use app context resources to avoid NotFoundException
// https://github.com/square/leakcanary/issues/2137
val resources = rootView.context.applicationContext.resources
resources.getBoolean(R.bool.leak_canary_watcher_watch_dismissed_dialogs)
}
// Probably a DreamService
else -> true
}
}
// Android widgets keep detached popup window instances around.
POPUP_WINDOW -> false
TOOLTIP, TOAST, UNKNOWN -> true
}
// 最后返回的是是否需要追踪这个窗口
if (trackDetached) {
rootView.addOnAttachStateChangeListener(object : OnAttachStateChangeListener {
val watchDetachedView = Runnable {
reachabilityWatcher.expectWeaklyReachable(
rootView, "${rootView::class.java.name} received View#onDetachedFromWindow() callback"
)
}
override fun onViewAttachedToWindow(v: View) {
mainHandler.removeCallbacks(watchDetachedView)
}
override fun onViewDetachedFromWindow(v: View) {
mainHandler.post(watchDetachedView)
}
})
}
}
override fun install() {
Curtains.onRootViewsChangedListeners += listener
}
override fun uninstall() {
Curtains.onRootViewsChangedListeners -= listener
}
}检测内存泄漏的方法与Activity也大差不差了。
ServiceWatcher
class ServiceWatcher(private val reachabilityWatcher: ReachabilityWatcher) : InstallableWatcher {
...
override fun install() {
checkMainThread()
check(uninstallActivityThreadHandlerCallback == null) {
"ServiceWatcher already installed"
}
check(uninstallActivityManager == null) {
"ServiceWatcher already installed"
}
try {
swapActivityThreadHandlerCallback { mCallback ->
uninstallActivityThreadHandlerCallback = {
swapActivityThreadHandlerCallback {
mCallback
}
}
Handler.Callback { msg ->
// https://github.com/square/leakcanary/issues/2114
// On some Motorola devices (Moto E5 and G6), the msg.obj returns an ActivityClientRecord
// instead of an IBinder. This crashes on a ClassCastException. Adding a type check
// here to prevent the crash.
if (msg.obj !is IBinder) {
return@Callback false
}
if (msg.what == STOP_SERVICE) {
val key = msg.obj as IBinder
activityThreadServices[key]?.let {
onServicePreDestroy(key, it)
}
}
mCallback?.handleMessage(msg) ?: false
}
}
swapActivityManager { activityManagerInterface, activityManagerInstance ->
uninstallActivityManager = {
swapActivityManager { _, _ ->
activityManagerInstance
}
}
Proxy.newProxyInstance(
activityManagerInterface.classLoader, arrayOf(activityManagerInterface)
) { _, method, args ->
if (METHOD_SERVICE_DONE_EXECUTING == method.name) {
val token = args!![0] as IBinder
if (servicesToBeDestroyed.containsKey(token)) {
onServiceDestroyed(token)
}
}
try {
if (args == null) {
method.invoke(activityManagerInstance)
} else {
method.invoke(activityManagerInstance, *args)
}
} catch (invocationException: InvocationTargetException) {
throw invocationException.targetException
}
}
}
} catch (ignored: Throwable) {
SharkLog.d(ignored) { "Could not watch destroyed services" }
}
}
...
private fun onServiceDestroyed(token: IBinder) {
servicesToBeDestroyed.remove(token)?.also { serviceWeakReference ->
serviceWeakReference.get()?.let { service ->
reachabilityWatcher.expectWeaklyReachable(
service, "${service::class.java.name} received Service#onDestroy() callback"
)
}
}
}
...
}由于Service不怎么常用,且本人不太会,这里就稍微说一下。因为Service没有对外暴露监听方式,所以我们用的另外一种方法:启动的Service都会在ActivityThread有记录,在onDestroy()时,AMS会告诉这个ActivityThread某个Service要被销毁了,然后就会回调Service的onDestroy()。所以我们就通过hook AMS告诉ActivityThread的信息记录下AMS,这样就能在发生回调时进行监测了。hook技术我也基本不了解,大概就是通过一些特定的机制来插入一些自定义逻辑,比如这里就是在AMS执行任务时,拦截并记录下来了Service信息。
InternalLeakCanary
我们分析完了LeakCanary是如何进行监听的,接下来再来看看监听完后又干了什么,我们回到初始化时的manualInstall()方法:
@JvmOverloads
fun manualInstall(
application: Application,
retainedDelayMillis: Long = TimeUnit.SECONDS.toMillis(5),
watchersToInstall: List<InstallableWatcher> = appDefaultWatchers(application)
) {
...
// Requires AppWatcher.objectWatcher to be set
LeakCanaryDelegate.loadLeakCanary(application) //这里就是核心组件,用于检测泄漏和对堆转储的分析
watchersToInstall.forEach {
it.install()
}
// Only install after we're fully done with init.
installCause = RuntimeException("manualInstall() first called here")
}堆转储(Heap Dump),就是将堆内存中的内容(对象,数据等)保存到一个文件中,后缀名是.hprof
我们点开这个LeakCanaryDelegate类:
internal object LeakCanaryDelegate {
@Suppress("UNCHECKED_CAST")
val loadLeakCanary by lazy {
try {
// 通过反射实例化了InternalLeakCanary,并且调用了invoke()方法
val leakCanaryListener = Class.forName("leakcanary.internal.InternalLeakCanary")
leakCanaryListener.getDeclaredField("INSTANCE")
.get(null) as (Application) -> Unit
} catch (ignored: Throwable) {
NoLeakCanary
}
}
object NoLeakCanary : (Application) -> Unit, OnObjectRetainedListener {
override fun invoke(application: Application) {
}
override fun onObjectRetained() {
}
}
}因为InternalLeakCanary在另一个模块中,而他又是internal object,所以只能通过反射了,这里调用invoke()方法的原因在上面解释过了,这里就不多说了。我们看看InternalLeakCanary的invoke方法:
override fun invoke(application: Application) {
_application = application // 传入application
checkRunningInDebuggableBuild()
// 这里就是之前在ActivityWatcher中设置的onObjectRetainedListener()
AppWatcher.objectWatcher.addOnObjectRetainedListener(this)
// 创建GC触发器,这样GC更容易触发垃圾回收
val gcTrigger = GcTrigger.Default
val configProvider = { LeakCanary.config }
val handlerThread = HandlerThread(LEAK_CANARY_THREAD_NAME)
handlerThread.start()
val backgroundHandler = Handler(handlerThread.looper)
// 创建分析堆转储的启动器
heapDumpTrigger = HeapDumpTrigger(
application, backgroundHandler, AppWatcher.objectWatcher, gcTrigger,
configProvider
)
application.registerVisibilityListener { applicationVisible ->
this.applicationVisible = applicationVisible
heapDumpTrigger.onApplicationVisibilityChanged(applicationVisible)
}
registerResumedActivityListener(application)
addDynamicShortcut(application) // 桌面添加图标
// We post so that the log happens after Application.onCreate()
mainHandler.post {
// https://github.com/square/leakcanary/issues/1981
// We post to a background handler because HeapDumpControl.iCanHasHeap() checks a shared pref
// which blocks until loaded and that creates a StrictMode violation.
backgroundHandler.post {
SharkLog.d {
when (val iCanHasHeap = HeapDumpControl.iCanHasHeap()) {
is Yup -> application.getString(R.string.leak_canary_heap_dump_enabled_text)
is Nope -> application.getString(
R.string.leak_canary_heap_dump_disabled_text, iCanHasHeap.reason()
)
}
}
}
}
}之前在moveToRetain()里回调的方法就是在这里注册的:
@Synchronized private fun moveToRetained(key: String) {
removeWeaklyReachableObjects()
val retainedRef = watchedObjects[key] //通过唯一的UUID取出观察对象
if (retainedRef != null) {
retainedRef.retainedUptimeMillis = clock.uptimeMillis() //这个是关联对象被认为保留的时间
// 责任链模式
onObjectRetainedListeners.forEach { it.onObjectRetained() }
}
}然后我们看onObjectRetained的实现:
override fun onObjectRetained() = scheduleRetainedObjectCheck()我们看看这个scheduleRetainedObjectCheck()方法:
fun scheduleRetainedObjectCheck() {
if (this::heapDumpTrigger.isInitialized) {
heapDumpTrigger.scheduleRetainedObjectCheck()
}
}继续跟进:
fun scheduleRetainedObjectCheck(
delayMillis: Long = 0L
) {
val checkCurrentlyScheduledAt = checkScheduledAt
if (checkCurrentlyScheduledAt > 0) { // 通过记录时间戳来避免重复检测
return
}
checkScheduledAt = SystemClock.uptimeMillis() + delayMillis //记录时间
backgroundHandler.postDelayed({
checkScheduledAt = 0
checkRetainedObjects() // 检测留存的对象
}, delayMillis)
}然后我们再看看是如何检测留存的对象的:
private fun checkRetainedObjects() {
// 是否能够heap dump
val iCanHasHeap = HeapDumpControl.iCanHasHeap()
val config = configProvider()
if (iCanHasHeap is Nope) {
if (iCanHasHeap is NotifyingNope) { // 发送一个通知,点击后开始分析
// Before notifying that we can't dump heap, let's check if we still have retained object.
var retainedReferenceCount = objectWatcher.retainedObjectCount
if (retainedReferenceCount > 0) {
gcTrigger.runGc() // 调用一次GC,确保是否真的泄漏
retainedReferenceCount = objectWatcher.retainedObjectCount
}
val nopeReason = iCanHasHeap.reason()
// 判断是否达到阈值,前台是>=5个时会触发,后台是>=1个就会触发
val wouldDump = !checkRetainedCount(
retainedReferenceCount, config.retainedVisibleThreshold, nopeReason
)
if (wouldDump) {
val uppercaseReason = nopeReason[0].toUpperCase() + nopeReason.substring(1)
onRetainInstanceListener.onEvent(DumpingDisabled(uppercaseReason))
showRetainedCountNotification( // 通知
objectCount = retainedReferenceCount,
contentText = uppercaseReason
)
}
} else {
SharkLog.d {
application.getString(
R.string.leak_canary_heap_dump_disabled_text, iCanHasHeap.reason()
)
}
}
return
}
// 如果不能进行堆转储,
var retainedReferenceCount = objectWatcher.retainedObjectCount
if (retainedReferenceCount > 0) {
gcTrigger.runGc()
retainedReferenceCount = objectWatcher.retainedObjectCount
}
if (checkRetainedCount(retainedReferenceCount, config.retainedVisibleThreshold)) return
val now = SystemClock.uptimeMillis()
val elapsedSinceLastDumpMillis = now - lastHeapDumpUptimeMillis
if (elapsedSinceLastDumpMillis < WAIT_BETWEEN_HEAP_DUMPS_MILLIS) {
onRetainInstanceListener.onEvent(DumpHappenedRecently)
showRetainedCountNotification(
objectCount = retainedReferenceCount,
contentText = application.getString(R.string.leak_canary_notification_retained_dump_wait)
)
scheduleRetainedObjectCheck(
delayMillis = WAIT_BETWEEN_HEAP_DUMPS_MILLIS - elapsedSinceLastDumpMillis
)
return
}
dismissRetainedCountNotification()
val visibility = if (applicationVisible) "visible" else "not visible"
// 分析hprof文件
dumpHeap(
retainedReferenceCount = retainedReferenceCount,
retry = true,
reason = "$retainedReferenceCount retained objects, app is $visibility"
)
}总的来说,就是先看能不能进行堆转储,如果可以就发送通知,否则通过一些尝试再次分析,我们看一下他是如何分析hprof文件的:
private fun dumpHeap(
retainedReferenceCount: Int,
retry: Boolean,
reason: String
) {
val directoryProvider =
InternalLeakCanary.createLeakDirectoryProvider(InternalLeakCanary.application)
val heapDumpFile = directoryProvider.newHeapDumpFile() // 创建导出的文件夹
val durationMillis: Long
if (currentEventUniqueId == null) {
currentEventUniqueId = UUID.randomUUID().toString()
}
try {
InternalLeakCanary.sendEvent(DumpingHeap(currentEventUniqueId!!))
if (heapDumpFile == null) {
throw RuntimeException("Could not create heap dump file")
}
saveResourceIdNamesToMemory()
val heapDumpUptimeMillis = SystemClock.uptimeMillis()
KeyedWeakReference.heapDumpUptimeMillis = heapDumpUptimeMillis
durationMillis = measureDurationMillis {
configProvider().heapDumper.dumpHeap(heapDumpFile) // 主要方法,用系统导出堆转储文件
}
if (heapDumpFile.length() == 0L) {
throw RuntimeException("Dumped heap file is 0 byte length")
}
lastDisplayedRetainedObjectCount = 0
lastHeapDumpUptimeMillis = SystemClock.uptimeMillis()
objectWatcher.clearObjectsWatchedBefore(heapDumpUptimeMillis)
currentEventUniqueId = UUID.randomUUID().toString()
// 导出情况回调,并根据成功与否通知用户
InternalLeakCanary.sendEvent(HeapDump(currentEventUniqueId!!, heapDumpFile, durationMillis, reason))
} catch (throwable: Throwable) {
InternalLeakCanary.sendEvent(HeapDumpFailed(currentEventUniqueId!!, throwable, retry))
if (retry) {
scheduleRetainedObjectCheck(
delayMillis = WAIT_AFTER_DUMP_FAILED_MILLIS
)
}
showRetainedCountNotification(
objectCount = retainedReferenceCount,
contentText = application.getString(
R.string.leak_canary_notification_retained_dump_failed
)
)
return
}
}我们点进这个sendEvent()方法:
fun sendEvent(event: Event) {
for(listener in LeakCanary.config.eventListeners) {
listener.onEvent(event)
}
}我们再去看看LeakCanary.config.eventListeners,我们发现他最后回调到了RemoteWorkManagerHeapAnalyzer里面:
object RemoteWorkManagerHeapAnalyzer : EventListener {
private const val REMOTE_SERVICE_CLASS_NAME = "leakcanary.internal.RemoteLeakCanaryWorkerService"
internal val remoteLeakCanaryServiceInClasspath by lazy {
try {
Class.forName(REMOTE_SERVICE_CLASS_NAME)
true
} catch (ignored: Throwable) {
false
}
}
// 这里所传进来的event就是HeadDump
override fun onEvent(event: Event) {
if (event is HeapDump) {
val application = InternalLeakCanary.application
// 构建了一个workManagerRequest,这个OneTimeWorkRequest表示任务只会执行一次
val heapAnalysisRequest =
OneTimeWorkRequest.Builder(RemoteHeapAnalyzerWorker::class.java).apply { // 指定任务执行的工作类
val dataBuilder = Data.Builder()
.putString(ARGUMENT_PACKAGE_NAME, application.packageName)
.putString(ARGUMENT_CLASS_NAME, REMOTE_SERVICE_CLASS_NAME)
setInputData(event.asWorkerInputData(dataBuilder))
with(WorkManagerHeapAnalyzer) { // 任务内容在WorkManagerHeapAnalyzer里面
addExpeditedFlag()
}
}.build()
SharkLog.d { "Enqueuing heap analysis for ${event.file} on WorkManager remote worker" }
val workManager = WorkManager.getInstance(application) // 用WorkManager创建了一个异步任务
workManager.enqueue(heapAnalysisRequest) // 将构建好的heapAnalysisReques入队,开始排队执行
}
}
}然后我么看看这个任务执行的类:
internal class RemoteHeapAnalyzerWorker(appContext: Context, workerParams: WorkerParameters) :
RemoteListenableWorker(appContext, workerParams) {
override fun startRemoteWork(): ListenableFuture<Result> {
val heapDump = inputData.asEvent<HeapDump>()
val result = SettableFuture.create<Result>()
heapAnalyzerThreadHandler.post { // 开启子线程执行分析任务
val doneEvent = AndroidDebugHeapAnalyzer.runAnalysisBlocking(heapDump, isCanceled = {
result.isCancelled
}) { progressEvent ->
if (!result.isCancelled) {
InternalLeakCanary.sendEvent(progressEvent) // 将分析的进度发送出去
}
}
if (result.isCancelled) {
SharkLog.d { "Remote heap analysis for ${heapDump.file} was canceled" }
} else {
InternalLeakCanary.sendEvent(doneEvent) //结束任务
result.set(Result.success())
}
}
return result
}
override fun getForegroundInfoAsync(): ListenableFuture<ForegroundInfo> {
return applicationContext.heapAnalysisForegroundInfoAsync()
}
}heapAnalyzerThreadHandler这里主要就是在子线程里面把文件交给HeapAnalyzer分析hprof文件。
总结一下整体的工作流程:

线程优化
线程优化的思想就是采用线程池,避免程序中存在大量的Thread,因为线程池可以重用内部的线程,从而避免了线程的创建和销毁带来的性能开销,同时线程池还能有效地控制线程池的最大并发数,避免大量的线程因互相抢占系统资源从而导致阻塞现象的发生。因此我们尽量采用线程池而不是每次都创建一个Thread。

一些常用用法
ExecutorService executorService = Executors.newFixedThreadPool(2); //固定大小线程池
// 提交一个任务(Runnable)并获取执行结果
Future<?> future = executorService.submit(() -> {
// 任务代码
});
// 提交一个Runnable对象,不返回执行结果
executorService.execute(() -> {
// 任务代码
});
executorService.shutdown(); // 线程池的关闭
executorService.shutdownNow(); // 尝试停止所有正在执行的任务,并返回未执行的任务列表简单工作原理

饱和策略就是在线程池的工作线程都繁忙且任务队列已满时如何处理新提交的任务,包括抛出异常,由调用线程执行任务,丢弃任务等。
线程池的底层工作原理就不介绍了。
应用启动优化
启动优化在性能优化中同样也很重要,因为如果启动流畅度低且启动时长过长的话,用户可能就会非常不满意,很影响使用体验。
启动APP的方式有三种,分别是冷启动,热启动和温启动,我们来看一下这三种启动有什么区别:
- 冷启动:系统不存在APP进程时启动APP称为冷启动
- 热启动:按了Home键或其他情况App被切换到后台,再次启动APP的过程。
- 温启动:温启动包含了冷启动的一些操作,但APP进程依然存在。
显然,我们可以看出,启动最慢的是冷启动,最快的是热启动,那么我们需要优化的点就是在冷启动上面。
应用启动流程分析
应用启动过程整体分为两大阶段:Application启动阶段、Activity启动阶段。冷启动的启动流程如下:

Application启动时,空白的启动窗口会保留在屏幕上,直到系统首次完成绘制应用程序。此时,系统进程会交换应用程序的启动窗口,允许用户与应用程序进行交互。但是实际上app应该先有一个logo/启动画面再是页面(现在默认是白色背景加App的Icon)。之前我们可以在theme.xml里面的主题设置背景图片/颜色:
<style name="WelcomeTheme" parent="Theme.AppCompat.NoActionBar">
<!--设置背景颜色或者图片-->
<item name="android:windowBackground">@drawable/xxxx</item>
<!--设置没有ActionBar-->
<item name="android:windowNoTitle">true</item>
<!--设置顶部状态栏颜色-->
<item name="android:statusBarColor" >@color/xxxx</item>
</style>然后在AndroidManifest.xml中为初次加载的activity进行设置:
<activity
android:name=".ui.activity.LoginActivity"
android:exported="true"
android:theme="@style/WelcomeTheme">
<intent-filter>
<action android:name="android.intent.action.MAIN" />
<category android:name="android.intent.category.LAUNCHER" />
</intent-filter>
</activity>然后在activity的onCreate()还原主题就好了。但现在有个SplashScreen可以很方便的帮我们设置自定义启动图,这里不多介绍了。
最后执行application的onCreate()方法时,我们通常是自定义了一个application,然后在里面进行了一些初始化(如Arouter,看门狗等),这一步肯定会拖慢APP的启动速度,所以这里是我们优化的主要地方,可以通过异步加载,按需加载,预加载等方式进行优化。这里给一个用协程的示例:
class MainApplication : Application() {
override fun onCreate() {
super.onCreate()
// 主线程仅处理轻量级任务
initLightweightComponents()
// 异步初始化耗时组件
CoroutineScope(Dispatchers.IO).launch {
initHeavyComponents()
}
}
private fun initLightweightComponents() {
// 如 SharedPreferences、基础工具类
}
private suspend fun initHeavyComponents() {
// 如网络库、数据库、SDK 初始化
withContext(Dispatchers.IO) {
RetrofitClient.init()
RoomDatabase.init()
Analytics.init()
}
}
}而Activity的优化同样主要也是在onCreate()方法内,这个方法开销是最大的,所以我们一定不能在里面进行非常耗时的操作,否则会非常拖慢APP的启动速度。
布局优化也可以加快启动,这里在前面已经说过了。还可以缓存上一次加载的数据,防止启动时网络请求过慢导致加载速度变慢。
检测工具
AS自带日志工具

这里输入Displayed就能看到每个页面的启动时间了。

在终端输入adb shell am start -W 包名/包名.首屏Activity也能看到启动时间。
- LaunchState:代表启动方式
- TotalTime:代表启动时间,包含创建进程+Application 初始化+Activity 初始化到界面显示。
- WaitTime: 一般比TotalTime 大点,包含系统影响的耗时
TraceView
TraceView是以图形的形式展示执行时间、调用栈等信息,信息比较全面,包含所有线程。但使用TraceView会导致严重的性能开销,故无法区分是不是TraceView影响了启动时间。
还是在Profiler中,我们选择Find CPU这个选项,就会进行分析,我们就能看到CPU执行情况,线程列表以及线程占用CPU的情况等数据了。

Profiler支持四种方式显示执行的方法。
- Call Chart:通过执行的顺序显示,见上图。
- Flame Chart:通过火焰图显示。
- Top Down:自顶向下调用显示。
- Bottom Up:自底向上调用显示。
通过分析CPU使用的视图,可以大致定位下面的问题。
- 采集五六分钟的CPU使用信息,缩放视图至最小,全局观察CPU在监控过程中的使用情况。
Profiler会同步记录用户的触摸事件及页面跳转等事件。对比CPU的瞬时使用情况找出问题代码。- 选择记录一段时间片,重点分析这段时间片中各线程中的方法执行情况。
宏观分析可以看出CPU使用情况会出现峰值,我们就需要根据具体场景去判断定位解决问题来消除这个峰值。
SysTrace
Systrace是结合Android内核数据,生成HTML报告,从报告中我们可以看到各个线程的执行时间以及方法耗时和CPU执行时间等。但他比TraceView更轻量。
卡顿优化——ANR
ANR(Application Not Responding,应用无响应),指Android系统发现你的应用在特定时间内没有响应用户操作时,弹出的错误。是系统通过与之交互的组件以及用户交互进行超时监控,用来判断应用进程是否存在卡死或响应过慢的问题。
ANR有InputDispatchTimeout,BroadcastTimeout,ServiceTimeout,ContentProvider Timeout这几种类型,我们通常关注的是第一种,他代表的是对输入事件(如按键或触摸事件)5s内没响应。
- BroadcastQueue Timeout:比如前台广播在10s内未执行完成,后台60s。
- Service Timeout:比如前台服务在20s内未执行完成,后台服务Timeout时间是前台服务的10倍,200s。
- ContentProvider Timeout:内容提供者,在publish过超时10s。
ANR分析
我们先模拟一个ANR:
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
findViewById<Button>(R.id.btn_lick).setOnClickListener {
Thread.sleep(30000)
}
}
}这里点击按钮后会卡顿或者崩溃,导致ANR。此时系统会在/data/anr目录下创建ANR问题记录的文件,我们可以通过在控制台执行adb bugreport [导出目录]命令,他就会导出生成的bug报告到指定目录。
导出完成的提示:

然后我们解压缩,跟踪到/FS/data/anr目录下,就会有ANR问题日志文件了,我们打开这个文件可以看到:

可以得出他是由点击事件导致了Thread.sleep,从而发生了ANR。
导致ANR的原因
耗时操作发生ANR的原因分为应用层导致的和系统层导致的,并且很大概率是系统层导致的ANR。
应用层导致ANR:
- 函数阻塞,比如死循环,主线程IO以及处理大数据等
- 锁出错,比如主线程等待子线程的锁
- 内存紧张,系统分配给每个应用的内存都是有上限的,长期内存紧张会导致频繁内存交换,进一步导致应用超时。
系统层导致ANR:
- CPU被抢占,比如在前台玩游戏,可能导致后台广播被占
- 系统服务无法及时响应,系统服务能力有限,可能导致系统服务长时间不响应导致ANR
- 其他应用占用大量内存
ANR触发流程
主要就是分为两种,Service,Broadcast,ContentProvider为一种,Input为另一种。
Service,Broadcast,ContentProvider
整个流程就是埋炸弹,拆炸弹和引爆炸弹三个流程。我们以Service为例。
埋炸弹
在Activity中调用Service后,调用链如下:
ContextImpl.startService()->ContextImpl.startServiceCommon()->ActivityManagerService.startService()
->ActiveServices.startServiceLocked()->ActiveServices.startServiceInnerLocked()->ActiveServices.bringUpServiceLocked()
->ActiveServices.realStartServiceLocked()然后我们来看realStartServiceLocked()这个方法:
//com.android.server.am.ActiveServices.java
private final void realStartServiceLocked(ServiceRecord r,
ProcessRecord app, boolean execInFg) throws RemoteException {
......
bumpServiceExecutingLocked(r, execInFg, "create");
......
try {
//IPC通知app进程启动Service
app.thread.scheduleCreateService(r, r.serviceInfo,
mAm.compatibilityInfoForPackage(r.serviceInfo.applicationInfo),
app.getReportedProcState());
} catch (DeadObjectException e) {
} finally {
}
}
private final void bumpServiceExecutingLocked(ServiceRecord r, boolean fg, String why) {
scheduleServiceTimeoutLocked(r.app);
.....
}
final ActivityManagerService mAm;
// How long we wait for a service to finish executing.
static final int SERVICE_TIMEOUT = 20*1000;
// How long we wait for a service to finish executing.
static final int SERVICE_BACKGROUND_TIMEOUT = SERVICE_TIMEOUT * 10;
void scheduleServiceTimeoutLocked(ProcessRecord proc) {
//mAm是AMS,mHandler是AMS里面的一个Handler
Message msg = mAm.mHandler.obtainMessage(
ActivityManagerService.SERVICE_TIMEOUT_MSG);
msg.obj = proc;
//发个延迟消息给AMS里面的一个Handler,相当于在这里埋了一个炸弹
mAm.mHandler.sendMessageDelayed(msg,
proc.execServicesFg ? SERVICE_TIMEOUT : SERVICE_BACKGROUND_TIMEOUT); // 这里就是设置是前台还是后台服务时间
}在整个startService流程中,在app启动Service前,会给AMS的Handler发送一个延迟消息。当AMS收到这个消息时,就认为这个Service超时了,就会触发ANR。
拆炸弹
AMS那边检验通过后,app就开始启动Service,于是我们就看看ApplicationThread.scheduleCreateService()方法,这个方法是在binder线程里面执行的,所以我们需要换到主线程ActivityThread.handleCreateService()方法里面:
//android.app.ActivityThread.java
@UnsupportedAppUsage
private void handleCreateService(CreateServiceData data) {
......
Service service = null;
try {
//1. 初始化Service
ContextImpl context = ContextImpl.createAppContext(this, packageInfo);
Application app = packageInfo.makeApplication(false, mInstrumentation);
java.lang.ClassLoader cl = packageInfo.getClassLoader();
service = packageInfo.getAppFactory()
.instantiateService(cl, data.info.name, data.intent);
......
service.attach(context, this, data.info.name, data.token, app,
ActivityManager.getService());
//2. Service执行onCreate,启动完成
service.onCreate();
mServices.put(data.token, service);
try {
//3. Service启动完成,需要通知AMS
ActivityManager.getService().serviceDoneExecuting(
data.token, SERVICE_DONE_EXECUTING_ANON, 0, 0);
} catch (RemoteException e) {
}
} catch (Exception e) {
}
}然后再来看看启动完Service后AMS这边干了什么:
private void serviceDoneExecutingLocked(ServiceRecord r, boolean inDestroying,
boolean finishing) {
......
mAm.mHandler.removeMessages(ActivityManagerService.SERVICE_TIMEOUT_MSG, r.app);
......
}很显然,就是将之前那个延时消息移除掉,也就是执行“拆炸弹”,如果在规定时间内没有“拆炸弹”,那么就会引发ANR。
引爆炸弹
我们来看看发放延迟消息的具体的逻辑:
//com.android.server.am.ActivityManagerService.java
final MainHandler mHandler;
final class MainHandler extends Handler {
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
......
case SERVICE_TIMEOUT_MSG: {
//这个mServices是ActiveServices
mServices.serviceTimeout((ProcessRecord)msg.obj);
} break;
}
......
}
......
}
//com.android.server.am.ActiveServices.java
void serviceTimeout(ProcessRecord proc) {
String anrMessage = null;
synchronized(mAm) {
//计算是否有service超时
final long now = SystemClock.uptimeMillis();
final long maxTime = now -
(proc.execServicesFg ? SERVICE_TIMEOUT : SERVICE_BACKGROUND_TIMEOUT);
ServiceRecord timeout = null;
for (int i=proc.executingServices.size()-1; i>=0; i--) {
ServiceRecord sr = proc.executingServices.valueAt(i);
if (sr.executingStart < maxTime) {
timeout = sr;
break;
}
}
if (timeout != null && mAm.mProcessList.mLruProcesses.contains(proc)) {
anrMessage = "executing service " + timeout.shortInstanceName;
}
}
if (anrMessage != null) {
//有超时的Service,mAm是AMS,mAnrHelper是AnrHelper
mAm.mAnrHelper.appNotResponding(proc, anrMessage);
}
}如果收到SERVICE_TIMEOUT_MSG消息,那么就确认是超时了,就会让ActiveServices来确认是否超时,如果是,就调用AnrHelper辅助类触发ANR。
void appNotResponding(ProcessRecord anrProcess, String activityShortComponentName,
ApplicationInfo aInfo, String parentShortComponentName,
WindowProcessController parentProcess, boolean aboveSystem, String annotation) {
//添加AnrRecord到List里面
synchronized (mAnrRecords) {
mAnrRecords.add(new AnrRecord(anrProcess, activityShortComponentName, aInfo,
parentShortComponentName, parentProcess, aboveSystem, annotation));
}
startAnrConsumerIfNeeded();
}
private void startAnrConsumerIfNeeded() {
if (mRunning.compareAndSet(false, true)) {
//开个子线程来处理
new AnrConsumerThread().start();
}
}
private class AnrConsumerThread extends Thread {
@Override
public void run() {
AnrRecord r;
while ((r = next()) != null) {
......
//这里的r就是AnrRecord
r.appNotResponding(onlyDumpSelf);
......
}
}
}
private static class AnrRecord {
void appNotResponding(boolean onlyDumpSelf) {
//mApp是ProcessRecord
mApp.appNotResponding(mActivityShortComponentName, mAppInfo,
mParentShortComponentName, mParentProcess, mAboveSystem, mAnnotation,
onlyDumpSelf);
}
}可以看到这里开了个子线程,然后调用了appNotResponding这个方法来执行一系列ANR流程。
Input触发ANR
input触发ANR的机制与前面三个完全不同,他不会到了一定时间就会“爆炸”,而是在后续再次触发input事件时去检测上一次的input事件有没有超时,如果超时了,那么便会抛出ANR,反之则会重置超时的时间,不会抛出ANR,因为即使当次的事件超时了,只要后续没有新的事件触发,那么实际上是没有什么影响的,所以就不需要抛出ANR了。
ANR dump主要流程
ANR流程主要是在系统进程system_server中进行的,而我们很难监控到系统进程,因此我们只能从系统进程和应用层的一个边界去观察分析。我们以输入超时的路径为例:
1.ActivityManagerService#inputDispatchingTimedOut
2.AnrHelper#appNotResponding
3.AnrConsumerThread#run
4.AnrRecord#appNotResponding
5.ProcessRecord#appNotResponding
我们可以发现无论是inputTimeout还是上面分析过的serviceTimeout,最终都会调用AnrHelper的appNotResponding方法,然后一直走到ProcessRecord的这个方法,我们来看看这个方法:
//com.android.server.am.ProcessRecord.java
void appNotResponding(String activityShortComponentName, ApplicationInfo aInfo,
String parentShortComponentName, WindowProcessController parentProcess,
boolean aboveSystem, String annotation, boolean onlyDumpSelf) {
ArrayList<Integer> firstPids = new ArrayList<>(5);
SparseArray<Boolean> lastPids = new SparseArray<>(20);
mWindowProcessController.appEarlyNotResponding(annotation, () -> kill("anr",
ApplicationExitInfo.REASON_ANR, true));
long anrTime = SystemClock.uptimeMillis();
if (isMonitorCpuUsage()) {
mService.updateCpuStatsNow();
}
final boolean isSilentAnr;
synchronized (mService) {
//一些特殊的情况
// PowerManager.reboot() can block for a long time, so ignore ANRs while shutting down.
//正在重启
if (mService.mAtmInternal.isShuttingDown()) {
Slog.i(TAG, "During shutdown skipping ANR: " + this + " " + annotation);
return;
} else if (isNotResponding()) {
//已经处于ANR流程中
Slog.i(TAG, "Skipping duplicate ANR: " + this + " " + annotation);
return;
} else if (isCrashing()) {
//正在crash的状态
Slog.i(TAG, "Crashing app skipping ANR: " + this + " " + annotation);
return;
} else if (killedByAm) {
//app已经被killed
Slog.i(TAG, "App already killed by AM skipping ANR: " + this + " " + annotation);
return;
} else if (killed) {
//app已经死亡了
Slog.i(TAG, "Skipping died app ANR: " + this + " " + annotation);
return;
}
// In case we come through here for the same app before completing
// this one, mark as anring now so we will bail out.
//做个标记
setNotResponding(true);
// Log the ANR to the event log.
EventLog.writeEvent(EventLogTags.AM_ANR, userId, pid, processName, info.flags,
annotation);
// Dump thread traces as quickly as we can, starting with "interesting" processes.
firstPids.add(pid);
// Don't dump other PIDs if it's a background ANR or is requested to only dump self.
//沉默的anr : 这里表示后台anr
isSilentAnr = isSilentAnr();
if (!isSilentAnr && !onlyDumpSelf) {
int parentPid = pid;
if (parentProcess != null && parentProcess.getPid() > 0) {
parentPid = parentProcess.getPid();
}
if (parentPid != pid) firstPids.add(parentPid);
if (MY_PID != pid && MY_PID != parentPid) firstPids.add(MY_PID);
//遍历LRU进程的List,选择需要dump的进程
for (int i = getLruProcessList().size() - 1; i >= 0; i--) {
ProcessRecord r = getLruProcessList().get(i);
if (r != null && r.thread != null) {
int myPid = r.pid;
if (myPid > 0 && myPid != pid && myPid != parentPid && myPid != MY_PID) {
// 如果是Persistent的进程,添加进去
if (r.isPersistent()) {
firstPids.add(myPid);
if (DEBUG_ANR) Slog.i(TAG, "Adding persistent proc: " + r);
} else if (r.treatLikeActivity) {
// 如果带有BIND_TREAT_LIKE_ACTVITY标签的进程,添加进去
firstPids.add(myPid);
if (DEBUG_ANR) Slog.i(TAG, "Adding likely IME: " + r);
} else {
// 将其他进程添加到lastPids中
lastPids.put(myPid, Boolean.TRUE);
if (DEBUG_ANR) Slog.i(TAG, "Adding ANR proc: " + r);
}
}
}
}
}
}
......
int[] pids = nativeProcs == null ? null : Process.getPidsForCommands(nativeProcs);
ArrayList<Integer> nativePids = null;
if (pids != null) {
nativePids = new ArrayList<>(pids.length);
for (int i : pids) {
nativePids.add(i);
}
}
// For background ANRs, don't pass the ProcessCpuTracker to
// avoid spending 1/2 second collecting stats to rank lastPids.
StringWriter tracesFileException = new StringWriter();
// To hold the start and end offset to the ANR trace file respectively.
final long[] offsets = new long[2];
// 按照顺序dump进程的堆栈
File tracesFile = ActivityManagerService.dumpStackTraces(firstPids,
isSilentAnr ? null : processCpuTracker, isSilentAnr ? null : lastPids,
nativePids, tracesFileException, offsets);
......
}这里的pid是进程标识符,操作系统分配给每一个正在运行的进程一个唯一的PID,用于操作系统管理进程,以及让用户或程序去引用和操作特定进程。
首先是针对一些特殊情况,比如正在重启,已经处于ANR流程中,正在crash,app已被杀死则直接return,不需要处理ANR。
而isSilentAnr为表示当前是否是一个后台ANR,与前台ANR不同,后台ANR会直接杀死进程,而前台ANR会弹出无响应的弹窗。发生ANR进程对用户来说有感知那么就是前台ANR,否则就是后台ANR。
在选择需要dump的进程(获取进程的内存快照,如内存使用,线程状态,堆栈信息等)这一步,因为发生ANR时,系统为了方便定位问题,会dump很多信息到Trace文件中,而Trace文件还会记录与ANR相关联的进程的Trace信息,因为产生ANR的原因可能是其他进程抢占了许多资源。而需要被dump的进程分为很多类:
- firstPids: firstPids是首先需要被dump的进程。发生了ANR的进程,是一定要被dump的,优先级最高。如果是后台ANR,则不需要加入其他线程。如果不是后台ANR,则需要继续添加其他进程。 如果发生ANR的进程不是system_server进程,则需要添加system_server进程。
- extraPids: LRU进程List的其他进程,都会先添加到lastPids,然后会进一步选出最近CPU使用率高的进程组成extraPids。
- nativePids: 就是一些固定的native的系统进程。
然后我们看看是如何dump进程的堆栈的也就是最后那行代码:
public static Pair<Long, Long> dumpStackTraces(String tracesFile, ArrayList<Integer> firstPids,
ArrayList<Integer> nativePids, ArrayList<Integer> extraPids) {
// 最多dump 20秒
long remainingTime = 20 * 1000;
// First collect all of the stacks of the most important pids.
if (firstPids != null) {
int num = firstPids.size();
for (int i = 0; i < num; i++) {
final int pid = firstPids.get(i);
final long timeTaken = dumpJavaTracesTombstoned(pid, tracesFile, remainingTime);
remainingTime -= timeTaken;
if (remainingTime <= 0) {
Slog.e(TAG, "Aborting stack trace dump (current firstPid=" + pid
+ "); deadline exceeded.");
return firstPidStart >= 0 ? new Pair<>(firstPidStart, firstPidEnd) : null;
}
}
}
......
}这里就是根据顺序依次取出firstPids,nativePids,extraPids的pid,然后依次去dump这些进程中的所有线程,因为一个进程就有好多好多线程,更何况还有这么多进程,所以规定了最多dump20秒,超时就直接返回,然后我们从dumpJavaTracesTombstoned(pid, tracesFile, remainingTime)这里去看看详细的逻辑,最后追踪到了debuggerd_client#debuggerd_trigger_dump()。
bool debuggerd_trigger_dump(pid_t tid, DebuggerdDumpType dump_type, unsigned int timeout_ms, unique_fd output_fd) {
//pid是从AMS那边传过来的,即需要dump堆栈的进程
pid_t pid = tid;
//......
// Send the signal.
//从android_os_Debug_dumpJavaBacktraceToFileTimeout过来的,dump_type为kDebuggerdJavaBacktrace
const int signal = (dump_type == kDebuggerdJavaBacktrace) ? SIGQUIT : BIONIC_SIGNAL_DEBUGGER;
sigval val = {.sival_int = (dump_type == kDebuggerdNativeBacktrace) ? 1 : 0};
//sigqueue:在队列中向指定进程发送一个信号和数据,成功返回0
if (sigqueue(pid, signal, val) != 0) {
log_error(output_fd, errno, "failed to send signal to pid %d", pid); // 发送失败
return false;
}
//......
LOG(INFO) << TAG "done dumping process " << pid;
return true;
}这里就是AMS给需要dump的进程发送了一个SIGQUIT信号,当进程收到信号后就开始dump,这里就是系统层与应用层的边界。因此如果我们能监控到这个SIGQUIT信号的发送,就能感知到ANR。
简单来说,就是app发生了ANR后,会收集一些相关进程的PID(包括发生ANR的进程),并向这些进程发送SIGQUIT信号,进程收到SIGQUIT信号后开始dump堆栈,生成ANR Trace文件。
可以发现,一个进程发生ANR后的整个流程,只有dump堆栈信息时会发生在发生ANR的进程里,其他操作行为几乎全在系统进程里面。
ANR监控
上面在最开始提到过可以通过adb来导出bug报告,但是那种办法查看anr日志文件过于困难(可能是我太菜了),于是就还有另外两种方法来监控ANR。
ANR-WatchDog
如何使用
先导入依赖:
implementation("com.github.anrwatchdog:anrwatchdog:1.4.0")然后我们依然是以上面的代码为例,使用方法很简单,只需要在application里面创建ANR-WatchDog就可以监控全局的ANR了:
val anrWatchDog = ANRWatchDog()
anrWatchDog.start();当然你也可以自定义日志输出方式:
anrWatchDog.setANRListener {
Log.e("ANR-WatchDog", "ANR detected!", it);
}然后我们运行后点击按钮就能在日志看到报错:


就可以看到很详细的日志报告了,我们可以看到这里是因为在按键后Thread.sleep导致长时间未响应,抛出了ANR,还可以定位到出错代码位置,非常方便。
源码分析
源码很简单,只有两个源文件,这里简单分析下:
private final Handler _uiHandler = new Handler(Looper.getMainLooper());
private final int _timeoutInterval;
private String _namePrefix = "";
private boolean _logThreadsWithoutStackTrace = false;
private boolean _ignoreDebugger = false;
private volatile long _tick = 0;
private volatile boolean _reported = false;
private final Runnable _ticker = new Runnable() {
@Override public void run() {
_tick = 0;
_reported = false;
}
};
@SuppressWarnings("NonAtomicOperationOnVolatileField")
@Override
public void run() {
setName("|ANR-WatchDog|");
// 设定的超时时长,可以自己修改
long interval = _timeoutInterval;
while (!isInterrupted()) {
// _tick为标志,如果主线程执行了发送的这个消息,那么_tick就会被赋值为0
boolean needPost = _tick == 0;
// 把_tick加上一个超时的时长,主线程执行了才知道
_tick += interval;
if (needPost) {
// 向主线程发送_ticker消息
_uiHandler.post(_ticker);
}
// 让子线程休眠interval的时间,如果这之后_tick != 0,说明卡顿了,没来得及执行消息
try {
Thread.sleep(interval);
} catch (InterruptedException e) {
_interruptionListener.onInterrupted(e);
return ;
}
// 如果_tick不为0且没有被debug
if (_tick != 0 && !_reported) {
// 排除debug的情况
if (!_ignoreDebugger && (Debug.isDebuggerConnected() || Debug.waitingForDebugger())) {
Log.w("ANRWatchdog", "An ANR was detected but ignored because the debugger is connected (you can prevent this with setIgnoreDebugger(true))");
_reported = true;
continue ;
}
// 自定义一个Interceptor告诉WatchDog,当前上下文环境是否可以上报
interval = _anrInterceptor.intercept(_tick);
if (interval > 0) {
continue;
}
// 上报线程堆栈
final ANRError error;
if (_namePrefix != null) {
error = ANRError.New(_tick, _namePrefix, _logThreadsWithoutStackTrace);
} else {
error = ANRError.NewMainOnly(_tick);
}
// 进行回调
_anrListener.onAppNotResponding(error);
interval = _timeoutInterval;
_reported = true;
}
}
}Watch-Dog的本质实际上是继承的一个Thread,即开个子线程,不断往主线程发送消息,如果超时了还没执行消息,那么就判定为可能发生了ANR。
监控SIGQUIT信号
前面我们提到当收到SIGQUIT信号时开始堆栈,因此我们可以监听或者拦截SIGQUIT的信号,但是会容易发生一些误报,漏报的情况。解决了这些问题就可以实现一个比较完整的ANR监控了,具体的方案可以自己去网上查找学习(太底层了有点看不懂😭)。
具体的监控ANR的逻辑可以去看matrix仓库。
Trace文件分析&&ANR案例分析
上面我们只是简单的模拟了一个ANR然后定位了出问题的位置,这里我们详细说一下具体的分析以及一些案例(案例源于网上)。
Trace文件分析
在前面的ANR分析中,我们通过adb bugreport [导出目录]命令导出了整个应用的bug报告,在/FS/data/anr包下不仅有ANR的日志记录文件,还有我们的trace文件,我们打开来分析一下:
----- pid 1865 at 2025-07-02 16:21:19.818055120+0800 -----
Cmd line: com.chaoxing.mobile
Build fingerprint: 'vivo/V2218A/V2218A:12/V417IR/913:user/release-keys'
ABI: 'x86_64'
Build type: optimized
Zygote loaded classes=20024 post zygote classes=8711
Dumping registered class loaders
#0 dalvik.system.PathClassLoader: [], parent #1
#1 java.lang.BootClassLoader: [], no parent
#2 dalvik.system.PathClassLoader: [...], parent #1
#3 dalvik.system.PathClassLoader: [/system/product/app/webview/webview.apk], parent #1
Done dumping class loaders
Classes initialized: 0 in 0
Intern table: 37019 strong; 957 weak
JNI: CheckJNI is off; globals=496 (plus 68 weak)
Libraries: ... (23)
// 已分配堆内存32MB,其中29MB已用,有218118个对象
Heap: 6% free, 29MB/32MB; 218118 objects
Total number of allocations 2207826 // 进程创建到现在一共有多少对象
Total bytes allocated 182MB // 进程创建到现在一共申请了多少内存
Total bytes freed 152MB // 进程创建到现在一共释放了多少内存
Free memory 2165KB // 不扩展堆的情况下可用的内存
Free memory until GC 2165KB // GC前的可用内存
Free memory until OOME 482MB // OOM之前的可用内存,如果这个值很小,那么可能说明app内存紧张
Total memory 32MB // 总内存,这里表示目前只申请了这么多内存
Max memory 512MB // 进程最多能申请的内存
... // 省略GC相关的信息
// 当前共91个线程
DALVIK THREADS (91):
// Signal Catcher线程调用栈
"Signal Catcher" daemon prio=10 tid=5 Runnable
| group="system" sCount=0 ucsCount=0 flags=0 obj=0x12c00390 self=0x7b560d1b32c0
| sysTid=1872 nice=-20 cgrp=default sched=0/0 handle=0x7b5488fcacf0
| state=R schedstat=( 1338863 0 4 ) utm=0 stm=0 core=0 HZ=100
| stack=0x7b5488ed4000-0x7b5488ed6000 stackSize=987KB
| held mutexes= "mutator lock"(shared held)
native: #00 pc 000000000073dbef ...
native: #01 pc 0000000000883850 ...
native: #02 pc 00000000008a45da ...
native: #04 pc 000000000089c6fb ...
native: #05 pc 000000000089bf0f ...
native: #06 pc 00000000008371f8 ...
native: #07 pc 000000000084d324 ...
native: #08 pc 000000000084c095 ...
native: #09 pc 00000000000cc9fa ...
native: #10 pc 00000000000639b7 ...
"main" prio=5 tid=1 Native
| group="main" sCount=1 ucsCount=0 flags=1 obj=0x728641c8 self=0x7b560d1ac380
| sysTid=1865 nice=0 cgrp=default sched=0/0 handle=0x7b575403f520
| state=S schedstat=( 2714047895 1267425784 2361 ) utm=155 stm=115 core=2 HZ=100
| stack=0x7ffce5ace000-0x7ffce5ad0000 stackSize=8188KB
| held mutexes=
native: #00 pc 00000000000b78aa ...
native: #01 pc 000000000001a00a ...
native: #02 pc 0000000000019eae ...
native: #03 pc 000000000016ab13 ...我们来具体解释一下trace的参数:
// Signal Catcher线程调用栈
"Signal Catcher" daemon prio=10 tid=5 Runnable
| group="system" sCount=0 ucsCount=0 flags=0 obj=0x12c00390 self=0x7b560d1b32c0
| sysTid=1872 nice=-20 cgrp=default sched=0/0 handle=0x7b5488fcacf0
| state=R schedstat=( 1338863 0 4 ) utm=0 stm=0 core=0 HZ=100
| stack=0x7b5488ed4000-0x7b5488ed6000 stackSize=987KB
| held mutexes= "mutator lock"(shared held)"Signal Catcher" daemon prio=10 tid=5 Runnable
"Signal Catcher" daemon:线程名,有daemon为守护线程(用来支持和服务其他线程)
prio:线程优先级(数字越小优先级越高)
tid:线程内部id
线程状态:Runnable
有下面几种状态分类(源于网上):
| Thread.java中定义的状态 | Thread.cpp中定义的状态 | 说明 |
|---|---|---|
| Terminated | Zombie | 线程死亡,终止运行 |
| Runnable | Running/Runnable | 线程可运行/正在运行 |
| Timed_Waiting | Timed_Wait | 执行了带有超时参数的wait/sleep/join函数 |
| Blocked | Monitor | 线程阻塞 |
| Waiting | Wait | 执行了无超时参数的wait函数 |
| New | Initializing | 新建,初始化 |
| New | Starting | 新建,正在启动 |
| Runnable | Native | 正在执行JNI本地函数 |
| Waiting | VMWait | 正在等待VM资源 |
| Runnable | Unknown | 未知状态 |
| Suspend | 线程暂停,通常是由于GC/Debug导致 |
一般来说:main线程处于BLOCK、WAITING、TIMEWAITING状态,基本上是函数阻塞导致的ANR,如果main线程无异常,则应该排查CPU负载和内存环境。
group="system" sCount=0 ucsCount=0 flags=0 obj=0x12c00390 self=0x7b560d1b32c0
- group:线程所属的线程组
- sCount:线程挂起次数
- dsCount:用于调试的线程挂起次数
- obj:当前线程关联的Java线程对象
- self:当前线程地址
sysTid=1872 nice=-20 cgrp=default sched=0/0 handle=0x7b5488fcacf0
- sysTid:线程真正意义上的tid
- nice:调度优先级,值越小则优先级越高
- cgrp:进程所属的进程调度组
- sched:调度策略
- handle:函数处理地址
state=R schedstat=( 1338863 0 4 ) utm=0 stm=0 core=0 HZ=100
state:线程状态
schedstat:CPU调度时间统计(schedstat括号中的3个数字依次是Running、Runable、Switch,Running时间:CPU运行的时间,单位ns,Runable时间:RQ队列的等待时间,单位ns,Switch次数:CPU调度切换次数)
utm/stm:用户态/内核态的CPU时间
core:该线程的最后运行所在核
HZ: 时钟频率
stack=0x7b5488ed4000-0x7b5488ed6000 stackSize=987KB
- stack:线程栈的地址区间
- stackSize:栈的大小
held mutexes= "mutator lock"(shared held)
- mutex:所持有mutex(互斥锁)类型,有独占锁exclusive和共享锁shared两类
独占锁exclusive:一个线程独自持有,别人进不来。
共享锁shared:多个线程可以同时持有。
mutator lock是 JVM/ART 为了同步 GC(垃圾回收)和普通代码执行而设的一把大锁:
- GC 线程要做 stop-the-world 时,要独占(exclusive)mutator lock,这样所有 mutator 线程都会暂停。
- 普通线程运行时,是以“共享”方式持有 mutator lock,这样大家可以一起跑,但 GC 进不来。
ANR案例分析
主线程无卡顿,处于正常堆栈
"main" prio=5 tid=1 Native
| group="main" sCount=1 dsCount=0 flags=1 obj=0x74b38080 self=0x7ad9014c00
| sysTid=23081 nice=0 cgrp=default sched=0/0 handle=0x7b5fdc5548
| state=S schedstat=( 284838633 166738594 505 ) utm=21 stm=7 core=1 HZ=100
| stack=0x7fc95da000-0x7fc95dc000 stackSize=8MB
| held mutexes=
kernel: __switch_to+0xb0/0xbc
kernel: SyS_epoll_wait+0x288/0x364
kernel: SyS_epoll_pwait+0xb0/0x124
kernel: cpu_switch_to+0x38c/0x2258
native: #00 pc 000000000007cd8c /system/lib64/libc.so (__epoll_pwait+8)
native: #01 pc 0000000000014d48 /system/lib64/libutils.so (android::Looper::pollInner(int)+148)
native: #02 pc 0000000000014c18 /system/lib64/libutils.so (android::Looper::pollOnce(int, int*, int*, void**)+60)
native: #03 pc 00000000001275f4 /system/lib64/libandroid_runtime.so (android::android_os_MessageQueue_nativePollOnce(_JNIEnv*, _jobject*, long, int)+44)
at android.os.MessageQueue.nativePollOnce(Native method)
at android.os.MessageQueue.next(MessageQueue.java:330)
at android.os.Looper.loop(Looper.java:169)
at android.app.ActivityThread.main(ActivityThread.java:7073)
at java.lang.reflect.Method.invoke(Native method)
at com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:536)
at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:876)这里的主线程看起来非常正常,如果还是发生了ANR:
- dump堆栈太晚了,即ANR已经过去了才开始dump堆栈,此时主线程当然是正常的了。
- CPU抢占等其他因素引起
此时我们要先去分析CPU、内存的使用情况。其次可以关注抓取日志的时间和ANR发生的时间是否相隔太久,时间太久这个堆栈就没有分析的意义了。
主线程执行耗时操作
这里在上面引入时提到过了,不多说了。
CPU被抢占
CPU usage from 0ms to 10625ms later (2020-03-09 14:38:31.633 to 2020-03-09 14:38:42.257):
543% 2045/com.test.demo: 54% user + 89% kernel / faults: 4608 minor 1 major //注意看这里
99% 674/[email protected]: 81% user + 18% kernel / faults: 403 minor
24% 32589/com.wang.test: 22% user + 1.4% kernel / faults: 7432 minor 1 major
......此时进程占据CPU高达543%,会导致ANR,这种ANR与我们的app无关。
Perfetto
Perfetto 是 google 从 Android10 开始引入的一个全新的平台级跟踪分析工具。它可以记录 Android 系统运行过程中的关键数据,并通过图形化的形式展示这些数据。Perfetto 不仅可用于系统级的性能分析,也是我们学习系统源码流程的好帮手。
Trace抓取
使用命令行抓取Trace
我们将AS链接好手机后,执行下面的命令:
adb shell perfetto -o /data/misc/perfetto-traces/trace_file.perfetto-trace -t 20s \ sched freq idle am wm gfx view binder_driver hal dalvik camera input res memory
这个命令会启动20s的追踪,并将跟踪文件保存到/data/misc/perfetto-traces/trace_file.perfetto-trace目录下,然后我们将trace文件导出就可以了:
adb pull /data/misc/perfetto-traces/trace_file.perfetto-trace
就抓取完了。
使用record_android_trace命令抓取
这是perfetto团队提供的一个脚本,能使我们的抓取变得更简单。
# 可能需要梯子
curl -O https://raw.githubusercontent.com/google/perfetto/master/tools/record_android_trace chmod u+x record_android_trace ./record_android_trace -o trace_file.perfetto-trace -t 10s -b 64mb \ sched freq idle am wm gfx view binder_driver hal dalvik camera input res memory我这里折腾半天还是Could not resolve host,不知道怎么回事。record_android_trace 命令能自动处理好路径,抓取完成后自动打开 Trace 文件。
使用UI工具抓取
Perfetto 也提供了图形化的工具来抓取 Trace,这种方法更简单直观。我们最常用的也是这种。
首先使用USB链接手机后,打开网站完成基本的设置(这里使用模拟器貌似连不上,还没查找到解决方案):

然后点击==Buffers and duration==,选择抓取的模式:

- stop when full,抓取的trace达到设置的容量后就停止(常用)
- Ring buffer,环形缓存,设置的容量满后会被覆盖
- Long Trace,一直记录
第二步,配置我们抓取的内容:

这里我们把CPU,APP以及调用栈的选项都勾上,像电量和内存这些可以自行选择。然后点击启动就可以开始抓取Trace了。

抓取完成后会自动打开Trace文件,非常方便啊。
基本使用
我们抓取完Trace后会自动打开:

左边是操作区我们主要关注Current Trace这里:
- show timeline: 显示当前Trace
- Query:写SQL查询语句
- Metrics: 官方给出的一些分析结果
- INFO and stats:当前Trace和手机app的一些信息
右边最上面是信息区,是时间与搜索。中间的是Trace内容区,是图形化展示Trace的区域。最底部是信息区,展示Trace内容区中选择中的元素的详细信息。
Perfetto Trace的操作有很多快捷键,比如w/s是放大/缩小,a/d是左/右移动,鼠标点击是选择,下面贴一下官方文档中出现的快捷键说明:

其中快捷键用的多的是这几个:
f是按住后点击片段即可放大选中
m是临时Mark一段区域,用来上下看时间、看其他进程信息等。临时的意思就是你如果按 m 去 mark 另外一个区域,那么上一个用 m mark 出来的 Mark 区域就会消失。退出临时选中:esc ,或者选择其他的 Slice 按 m,当前这个 Slice 的选中效果就会消失:
选中一个片段以后,如果点击 shift + m,就会添加一个普通标记,当标记另一个片段以后,普通标记不会被取消。
q:隐藏和显示信息Tab,由于 Perfetto 非常占屏幕,熟练使用 q 键很重要,看的时候快速打开,看完后快速关闭。
插旗子:Perfetto 还可以通过插旗子的方法来在 Trace 上做标记,Perfetto 支持你把鼠标放到 Trace 最上面,就会出现一个旗子,点击左键即可插一个旗子在上面,方便我们标记某个事件发生,或者某个时间点
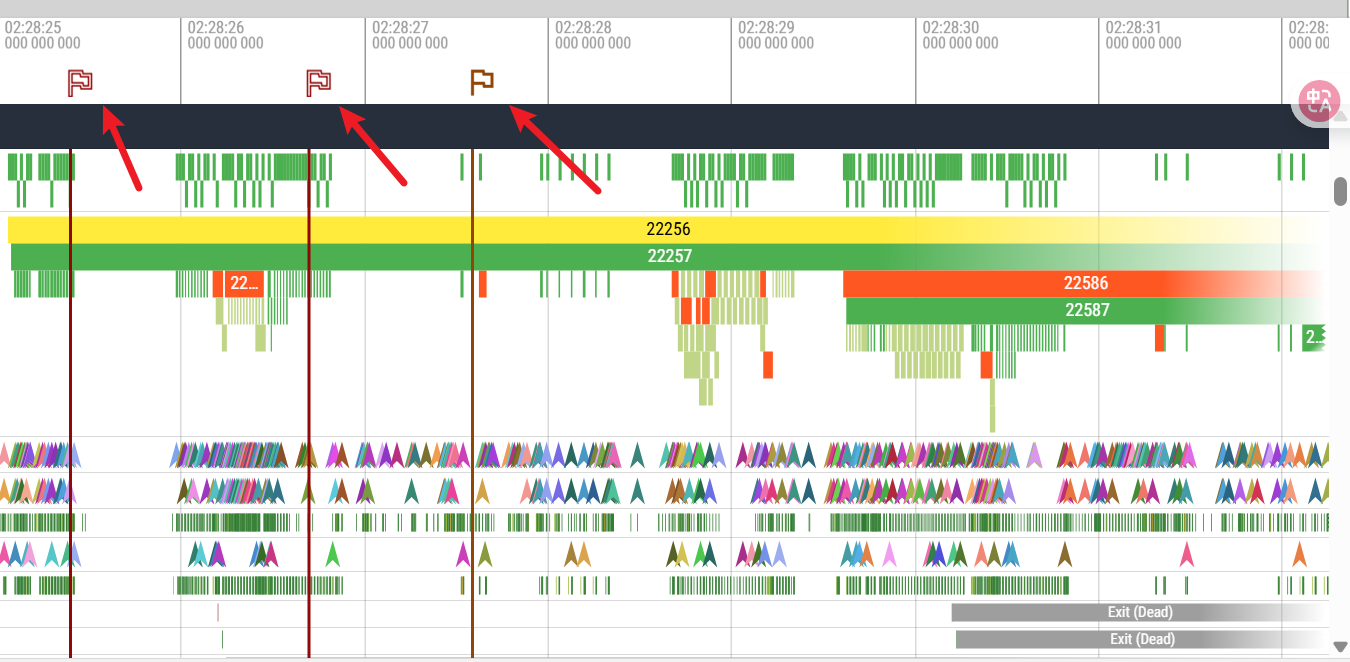
然后我们来详细看一下内容区:
Slice片段

点击内容区的方块后会被黑框框住,然后下面的信息区会显示相关信息:
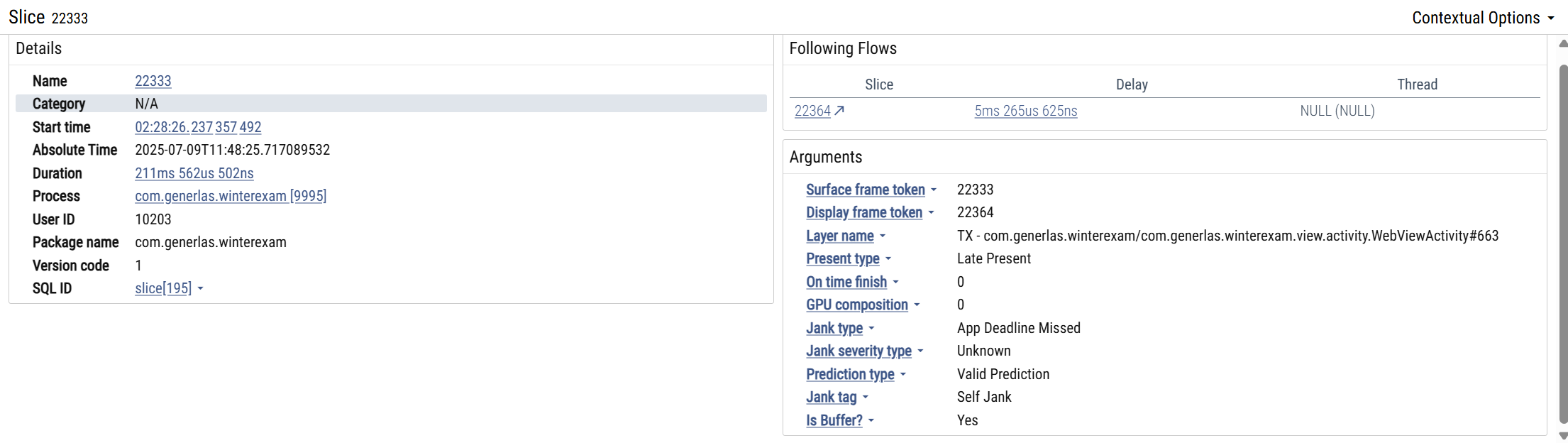
Slice代表了一段代码的执行过程,在代码中起于 Trace.traceBegin\ATRACE_BEGIN,终于 Trace.traceEnd\ATRACE_END
CPU Sched Slice
用于展示CPU的调度情况:
thread_state
点击片段上方线程调度信息片段(Running),可以看到线程当前运行在哪个CPU上:
比如我们这里定位到main thread字样这儿,点击绿色的Running片段,在下方我们就可以看到线程是运行在CPU 7上的,然后我们点击这个Running on CPU 7,就能跳转到CPU调度区域中:

再次点击信息区域的斜箭头,可以回到原来位置:
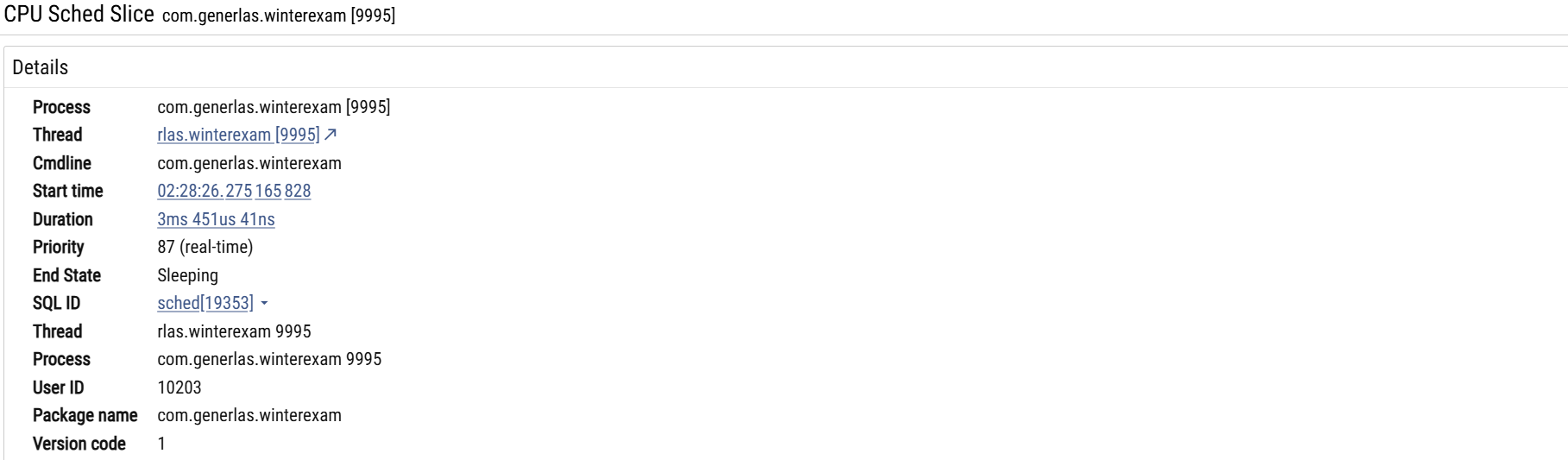
这里选择的 thread_state 是 App 的主线程,由用户点击屏幕唤醒运行,实际很多线程都是由其他线程/进程唤醒的,比如在 CPU 调度区域中选择一个 Slice:
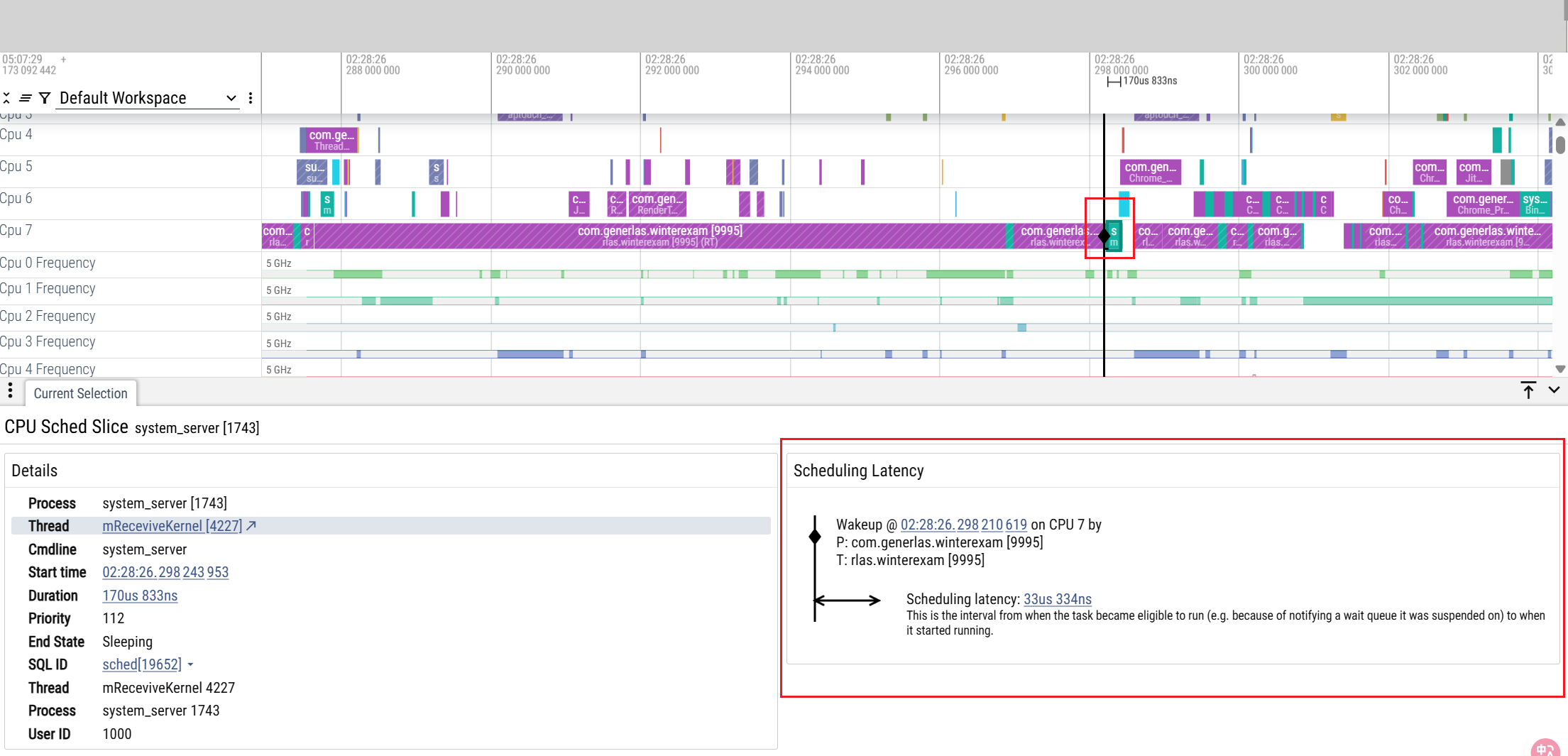
比如这里就是由P:com.generals.winterexam[9995]中的T:rlas.winterexam[9995]唤醒的,从就绪到运行延迟了33us 334ns。
Pin操作

通过这个按钮可以将这一行的信息pin到最顶部。
快速查看APP超时
由于 Android 多 Buffer 机制的存在,App 执行超时不一定会卡顿,但是超时是需要我们去关注的。通过 Perfetto 提供给的 Expected Timeline 和 Actual Timeline 这两行,可以清楚看到执行超时的地方。

Actual Timeline这里标红了表示这一帧执行超时了,可能引起卡顿。然后信息栏还会显示掉帧原因:

这里的Jank type就是掉帧原因了。App Deadline Missed就是应用错过了渲染截止时间,导致系统无法按时提交本帧到屏幕,于是掉帧卡顿,这里在前面绘制优化已经详细说过。
CPU信息分析
查看CPU频率
我们这里先选取一段slice:

然后点击State里面的CPU进行跟踪:

然后查看对应的Frequency片段的频率就可以了。
查看CPU占用率

我们先选出一段时间段,然后在下面能看到CPU线程/进程的时间占用情况,从上到下可以看到每个线程/进程的 CPU 占用情况,越上面的线程/进程占用时间越多。
CPU占用率=CPU占用时间/总时间/核心数,比如上面的CPU占用率就是30.59/32.56/8=11.7%。
线程状态分析
操作区的 thread_state slice 用于展示线程的运行状态。主要有以下几种类型:
- Running,深绿色
- Runnable,浅绿色
- Sleeping,白色
- Uninterruptible Sleep (IO),橙色
- Uninterruptible Sleep (Non IO),紫红色
Running

深色表示线程处于运行状态,正在正常执行代码逻辑。Priority表示线程优先级,Previous/Next State表示前后状态,Woken by是唤醒源,Woken threads是唤醒目标。
Runnable
浅绿色表示线程处于可运行状态(Runnable),线程正在等待调度器的调度上 CPU 执行。上图Running左边的就表示Runnable。
Sleeping
空白区域表示线程处于睡眠状态(Sleeping),多见于 epoll_wait 系统调用。
Uninterruptible Sleep (IO)

橙色区域代表 Uninterruptible Sleep (IO) 状态,一般线程在 IO 操作上阻塞了。 不可中断状态实际上是系统对进程和硬件设备的一种保护机制。比如,当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的。
Uninterruptible Sleep (Non IO)
紫红色区域代表 Uninterruptible Sleep (Non IO),一般是在等待锁或者是 Binder 远程调用。(还没见到过)
CPU调度情况分析

在CPU信息区域,我们可以看到每个线程/任务在 CPU 上的调度情况。当我们把鼠标放在某一个任务上时,该任务就会高亮,其他任务变成灰色,方便我们查看单个任务的调度情况:

总结
总的来看,Perfetto的功能是非常强大的,能帮我们提供非常全面的信息并且能用UI进行展示(但是界面也太复杂了吧)。而如果我们在一些简单的开发中,可以通过Perfetto来简单的定位,然后再用Profiler具体分析(感觉直接用Profiler也没问题,又方便也挺全面)。这里就不多对Perfetto进一步介绍了,扔篇文章以及一个利用Perfetto分析的视频在这儿:
Android Perfetto 系列 3:熟悉 Perfetto View
RV优化
RV的一些常规优化比如不要在onBind里面执行耗时操作/点击事件等就不多说了,这里主要说一下RV的局部刷新。
在RV中使用payloads可以实现局部刷新,避免整个item的重新绑定,从而提高性能。局部刷新通过 notifyItemChanged(position, payload) 来触发,payload 参数可以携带数据,指定更新内容,从而避免不必要的视图重建。
局部刷新的用法
局部刷新最主要的就是重写带payload参数的onBindViewHolder方法,下面简单写了个Adapter的示例:
class ExampleAdapter(private val items: List<MyItem>) : RecyclerView.Adapter<ExampleAdapter.ExampleViewHolder>() {
class ExampleViewHolder(view: View) : RecyclerView.ViewHolder(view) {
val titleView: TextView = view.findViewById(R.id.title)
val contentView: TextView = view.findViewById(R.id.content)
}
override fun onCreateViewHolder(parent: ViewGroup, viewType: Int): ExampleViewHolder {
val view = LayoutInflater.from(parent.context).inflate(R.layout.item_layout,parent,false)
return ExampleViewHolder(view)
}
// 全量绑定的方法,用于初次绑定视图或者payload为空时
override fun onBindViewHolder(holder: ExampleViewHolder, position: Int) {
val item = items[position]
holder.titleView.text = item.title
holder.contentView.text = item.content
}
// 重写带payload参数的onBindViewHolder
override fun onBindViewHolder(
holder: ExampleViewHolder,
position: Int,
payloads: MutableList<Any>
) {
if(payloads.isEmpty()) {
// payloads为空,进行全量绑定
super.onBindViewHolder(holder, position, payloads)
} else {
// 取出payload
val bundle = payloads[0] as Bundle
// 用if判断更新的类型进行更新
if(bundle.containsKey("title")) {
holder.titleView.text = bundle.getString("title")
}
if(bundle.containsKey("content")) {
holder.contentView.text = bundle.getString("content")
}
}
}
// 暴露给外部的局部刷新方法
fun updateTitle(position: Int, newTitle: String) {
items[position].title = newTitle
val payload = Bundle()
payload.putString("title",newTitle)
// 调用局部刷新的方法
notifyItemChanged(position,payload)
}
fun updateContent(position: Int, newContent: String) {
items[position].content = newContent
val payload = Bundle()
payload.putString("content", newContent)
notifyItemChanged(position, payload)
}
override fun getItemCount() = items.size
}使用场景:
- 数据部分的变化
- 提高性能:当
item复杂,整体刷新成本高时,使用payload避免整个item重建 - 局部交互:比如点击后只改变点击图标,也可以用payload刷新
局部刷新的原理
我们在使用notifyItemChanged(position)时,比如列表有进度条需要不停更新数据,或者在滑动时刷新,会出现重影/闪烁的问题。此时如果我们换成notifyItemChanged(position,0),那么这个问题就解决了。为什么会这样呢?我们来看看源码:
public final void notifyItemChanged(int position, @Nullable Object payload) {
mObservable.notifyItemRangeChanged(position, 1, payload);
}可以看到这里的payload参数是一个Object对象,我们点进mObservable对象的这个方法:
public void notifyItemRangeChanged(int positionStart, int itemCount,
@Nullable Object payload) {
// since onItemRangeChanged() is implemented by the app, it could do anything, including
// removing itself from {@link mObservers} - and that could cause problems if
// an iterator is used on the ArrayList {@link mObservers}.
// to avoid such problems, just march thru the list in the reverse order.
// 遍历集合取出对象
for (int i = mObservers.size() - 1; i >= 0; i--) {
mObservers.get(i).onItemRangeChanged(positionStart, itemCount, payload);
}
}这里调用的是AdapterDataObserver的onItemRangedChanged(),这是一个接口,他的实现是RecyclerViewDataObserver,我们来看看他的这个方法:
private class RecyclerViewDataObserver extends AdapterDataObserver {
...
@Override
public void onItemRangeChanged(int positionStart, int itemCount, Object payload) {
assertNotInLayoutOrScroll(null);
if (mAdapterHelper.onItemRangeChanged(positionStart, itemCount, payload)) {
triggerUpdateProcessor();
}
}
...
}triggerUpdateProcessor()方法:
void triggerUpdateProcessor() {
if (POST_UPDATES_ON_ANIMATION && mHasFixedSize && mIsAttached) {
ViewCompat.postOnAnimation(RecyclerView.this, mUpdateChildViewsRunnable);
} else {
mAdapterUpdateDuringMeasure = true;
requestLayout();
}
}这个方法简单来说就是在去重新请求布局requestLayout(),我们看上面的代码知道只有当if里面的条件满足后才会去重新请求布局。
我们再来看看调用的mAdapterHelper.onItemRangeChanged(positionStart, itemCount, payload)方法:
boolean onItemRangeChanged(int positionStart, int itemCount, Object payload) {
if (itemCount < 1) {
return false;
}
mPendingUpdates.add(obtainUpdateOp(UpdateOp.UPDATE, positionStart, itemCount, payload)); // 将payload包装成对象放入集合中
mExistingUpdateTypes |= UpdateOp.UPDATE;
return mPendingUpdates.size() == 1; // size == 1才返回true
}size == 1说明只有第一次调用时才会返回true去触发requestLayout,说明即使调用多次notify,也只有第一次才会触发requestLayout()。
现在我们再来看看在哪里调用了这个被包装的对象:
mCallback.markViewHoldersUpdated(op.positionStart, op.itemCount, op.payload);这里的mCallback也是一个接口,在RecyclerView的代码中有他的实现:
@Override
public void markViewHoldersUpdated(int positionStart, int itemCount, Object payload) {
viewRangeUpdate(positionStart, itemCount, payload);
mItemsChanged = true;
}再来看看这个viewRangeUpdate()函数:
void viewRangeUpdate(int positionStart, int itemCount, Object payload) {
final int childCount = mChildHelper.getUnfilteredChildCount();
final int positionEnd = positionStart + itemCount;
for (int i = 0; i < childCount; i++) {
final View child = mChildHelper.getUnfilteredChildAt(i);
final ViewHolder holder = getChildViewHolderInt(child);
if (holder == null || holder.shouldIgnore()) {
continue;
}
if (holder.mPosition >= positionStart && holder.mPosition < positionEnd) {
// We re-bind these view holders after pre-processing is complete so that
// ViewHolders have their final positions assigned.
holder.addFlags(ViewHolder.FLAG_UPDATE);
holder.addChangePayload(payload); //在这个函数里面把payload传了进去
// lp cannot be null since we get ViewHolder from it.
((LayoutParams) child.getLayoutParams()).mInsetsDirty = true;
}
}
mRecycler.viewRangeUpdate(positionStart, itemCount);
}我们可以看到这里调用了holder的addChangePayload方法,我们跟进:
void addChangePayload(Object payload) {
if (payload == null) {
addFlags(FLAG_ADAPTER_FULLUPDATE);
} else if ((mFlags & FLAG_ADAPTER_FULLUPDATE) == 0) {
createPayloadsIfNeeded(); // 创建新的payloads集合
mPayloads.add(payload); // 把当前的payload添加进集合里
}
}
private void createPayloadsIfNeeded() {
if (mPayloads == null) {
mPayloads = new ArrayList<Object>();
mUnmodifiedPayloads = Collections.unmodifiableList(mPayloads);
}
}
List<Object> getUnmodifiedPayloads() {
if ((mFlags & FLAG_ADAPTER_FULLUPDATE) == 0) {
if (mPayloads == null || mPayloads.size() == 0) {
// Initial state, no update being called.
return FULLUPDATE_PAYLOADS;
}
// there are none-null payloads
return mUnmodifiedPayloads;
} else {
// a full update has been called.
return FULLUPDATE_PAYLOADS;
}
}这里有两个list,mPayloads和mUnmodifiedPayloads,在getUnmodifiedPayloads中可以看到当mPayloads不为空才会返回mUnmodifiedPayloads,否则返回FULLUPDATE_PAYLOADS,即Collections.EMPTY_LIST。然后我们定位一下看到有处代码也调用了这个函数:
boolean canReuseUpdatedViewHolder(ViewHolder viewHolder) {
return mItemAnimator == null || mItemAnimator.canReuseUpdatedViewHolder(viewHolder,
viewHolder.getUnmodifiedPayloads());
}我们重点关注一下这个mItemAnimator,他也是一个接口,而他的实现类是DefaultItemAnimator,他实现的方法:
@Override
public boolean canReuseUpdatedViewHolder(@NonNull RecyclerView.ViewHolder viewHolder,
@NonNull List<Object> payloads) {
return !payloads.isEmpty() || super.canReuseUpdatedViewHolder(viewHolder, payloads);
}可以看到这里只要payloads不为空(是这个集合,哪怕payload为0都无所谓),就会返回true。
然后我们查找这个方法的用处,在RecyclerView中发现了这样一个函数:
void scrapView(View view) {
final ViewHolder holder = getChildViewHolderInt(view);
if (holder.hasAnyOfTheFlags(ViewHolder.FLAG_REMOVED | ViewHolder.FLAG_INVALID)
|| !holder.isUpdated() || canReuseUpdatedViewHolder(holder)) {
if (holder.isInvalid() && !holder.isRemoved() && !mAdapter.hasStableIds()) {
throw new IllegalArgumentException("Called scrap view with an invalid view."
+ " Invalid views cannot be reused from scrap, they should rebound from"
+ " recycler pool." + exceptionLabel());
}
holder.setScrapContainer(this, false);
mAttachedScrap.add(holder);
} else {
if (mChangedScrap == null) {
mChangedScrap = new ArrayList<ViewHolder>();
}
holder.setScrapContainer(this, true);
mChangedScrap.add(holder);
}
}可以看到如果这个函数为true,即payloads不为空,就会把holder放入mAttachedScrap中,否则放入mChangedScrap。
这两个东西貌似会涉及到缓存机制,没看过qaq,这里上网查了一下,大概就是mChangedScrap是与Rv分离的ViewHolder列表,即刷新的时候会移除重新bind。mAttachedScrap则是未与RV分离的ViewHolder列表,刷新时不需要重新bind,直接更新数据。
因此这下就明白了,没有payload时就需要重新bind,所以会出现闪烁。而如果使用了payload,就不会移除重新bind,只更新单个数据。
这里没有专门研究过RV的缓存原理,故只分析了为什么传入payload就会局部刷新,不传入payload就不会局部刷新。
这里再补充一下我们现在更多使用的是ListAdapter+DiffUtil实现差分刷新,这个方案非常高效,同时我们在实现接口时也可以用payload自定义局部刷新:
kotlinclass PersonDiffCallback : DiffUtil.ItemCallback<Person>() { // 比较item是否相同 override fun areItemsTheSame(oldItem: Person, newItem: Person): Boolean = oldItem.id == newItem.id // 比较内容是否相同 override fun areContentsTheSame(oldItem: Person, newItem: Person): Boolean = oldItem == newItem // 重写这个方法 override fun getChangePayload(oldItem: Person, newItem: Person): Any? { val bundle = Bundle() // 如果数据内容不一样则进行单独的局部刷新 if (oldItem.name != newItem.name) { bundle.putString("name", newItem.name) } if (oldItem.age != newItem.age) { bundle.putInt("age", newItem.age) } return if (bundle.size() == 0) null else bundle // 将payload返回 } }然后Adapter里面的方法还是同理,重写带payload的onBindViewHolder方法,代码可以见上面的,然后在提交时我们只需要一行代码:
kotlinadapter.submitList(newPersonList)就不用notifyItemChanged了。使用上面这种方案可以极大的优化性能流畅度以及使用体验。
总结
性能优化是一个非常庞大,宽泛的板块,不仅要学会去研究底层,去分析如何出现的性能问题,是什么原因导致的,还要掌握用什么工具去分析,如何查看分析的结果并针对实际场景对症下药,进行优化。由于时间有限,这里仅仅是一个基本入门,让我们有意识的会去查看分析性能,以及问题的根本来源,以及拿到trace文件等这些如何进行一些基本的分析。更深一步的比如Android底层原理等等就需要更进一步的学习了。